ちわ。seiです。タイトルの通りです。
DR(ディザスターリカバリー、災害復旧)構成、あるいは、冗長構成とかHA(高可用性)構成っていうのもほぼ同義かと思いますが、クラウドサービスを利用するとそんな構成が、あっという間に簡単に構築できます。オンプレだとサーバーラック内を冗長構成にするのすら、長い時間と労力と金がかかってたのに嘘のようです。しかも、サーバーラック内の冗長化だけじゃ地理的災害時のメリットが全くなしという・・・。
今回は、仮想ネットワークを利用しデータを全力で保護しつつ、データセンター障害やリージョン障害が発生しても「なんとか」(←ここ大事)稼働するWEBアプリを構築していきたいと思います。
今回のゴール
基本的にはMSさんLearnからの「データベースへのプライベート接続を使用したマルチリージョン Web アプリ」のオマージュ?となります。アーキテクチャー自体は理解できるんですが、「じゃあその構築手順は?」と言われると、なかなかに手間取ったので備忘録として。(まぁスキル不足でしかないっていう話ではあるんですが)。若干構成を変えてお財布に優しくしたつもりですが、金額算出したわけではないのでよくわかりません。悪しからず。

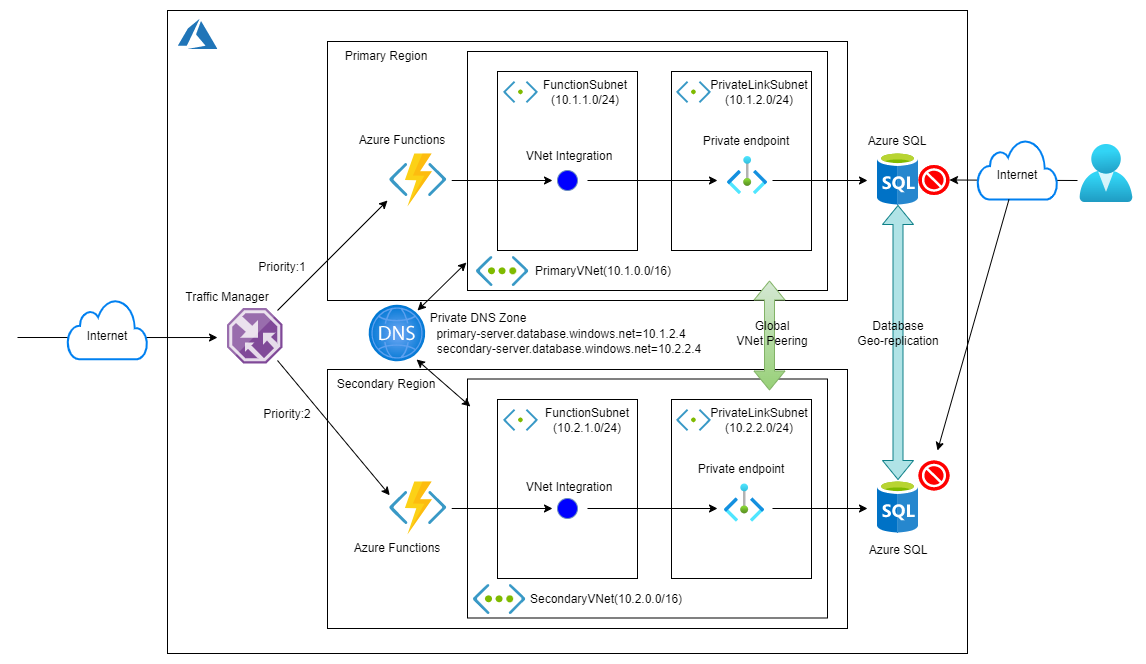
構成図は以下のようになります。
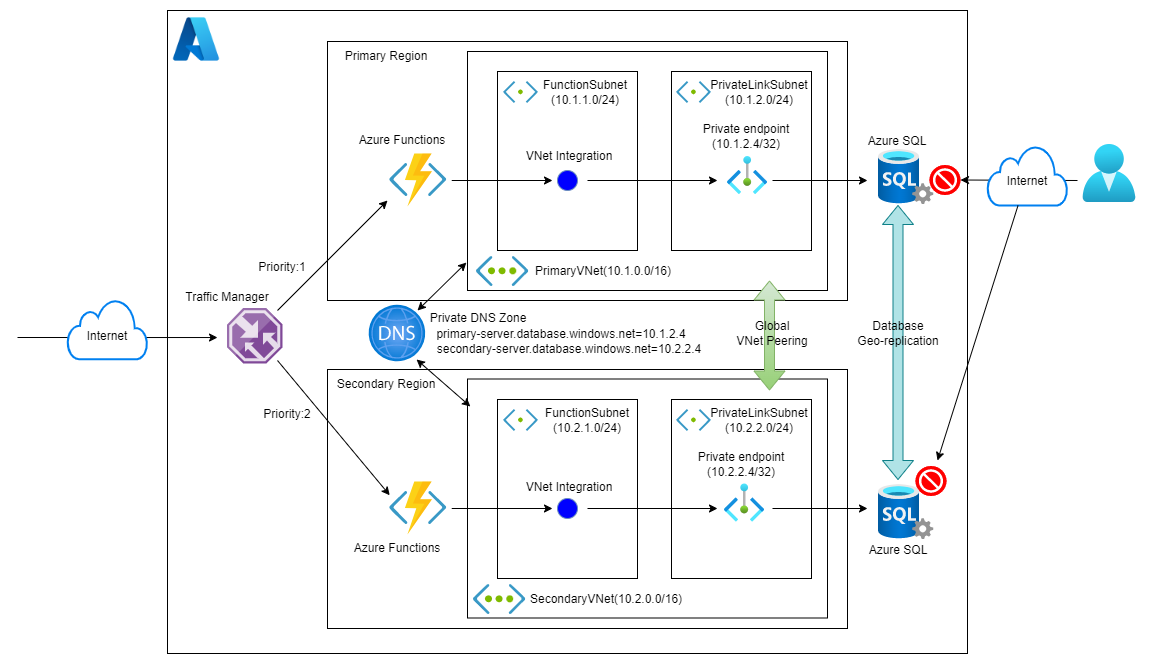
Azure Front Door、WAFはオミットしてます。必要ならば入れていただければ。代わりにTraffic Managerがリクエストを振り分ける形になります。実際はTraffic Managerの前にAzure Static Web Appsとかのフロントエンドを配置しないとWEBアプリとしては機能しないと思いますが、今回はDR構成の検証という感じですので、こんなので行かせていただきます。
※トークンの管理やAPIキーなどの考慮も行っていません。
また、各リソースの詳細な作成方法は一部省略させていただきます。
追記:Azure Front Doorを利用したDR構成例も投稿してみましたのでご参照ください。
DR(ディザスターリカバリー)構成の構築手順
リソースグループの作成
まずはリソースグループを作成していきます。災害対策として2つのリージョンに分散してリソースを作成していく必要があるでしょう。プライマリーリージョンとして「東日本」、セカンダリーリージョンとして「東南アジア」にそれぞれリソースグループを作っていきます。
→2023年6月現在、Azure西日本リージョンでもApp Serviceがデプロイできることを確認しています。一安心です。
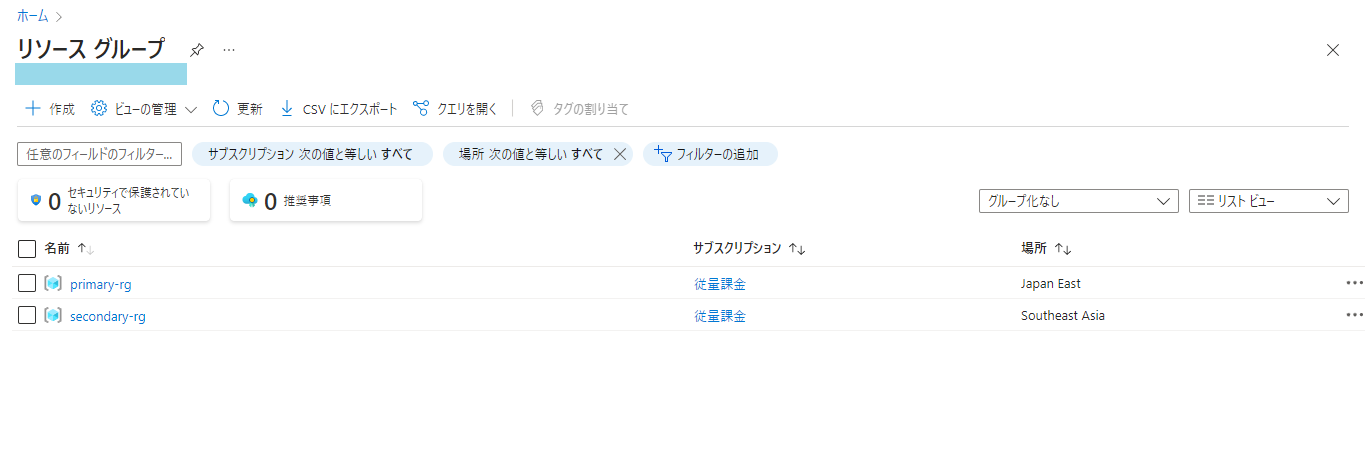
はい、このように「primary-rg」として「Japan East」に、「secondary-rg」として「Southeast Asia」それぞれにリソースグループを作成しました。それではリソースをぶっこんでいきましょう。
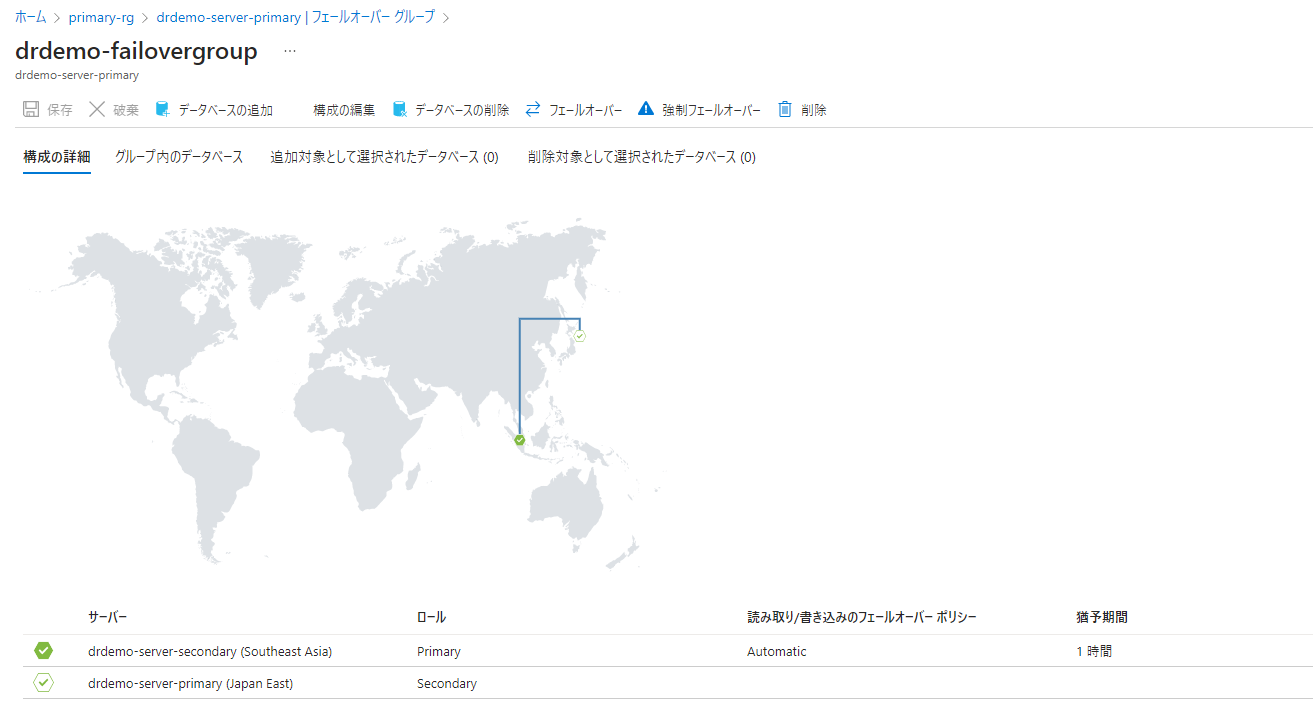
Azure SQL Databaseの作成&フェールオーバーグループ設定
まず、Azure SQL Databaseを用意していきましょう。プライマリーリージョンにはSQLサーバーとデータベースを作りますが、セカンダリーリージョンには論理SQLサーバーのみ作ります。その後、二つのリージョンをフェールオーバーグループに設定するとプライマリーに用意したデータベース内容が自動的にセカンダリーにレプリケートされます。
まずはプライマリーリージョンにSQL Databaseサーバーを新規で作成します。SQL認証を選択した場合は、プライマリーリージョンとセカンダリーリージョンのサーバー管理者ログインアカウント、パスワードを一致させた方がよいでしょう。一致していない場合、フェールオーバー後にAzure Functionsから恐らくアクセスできません。
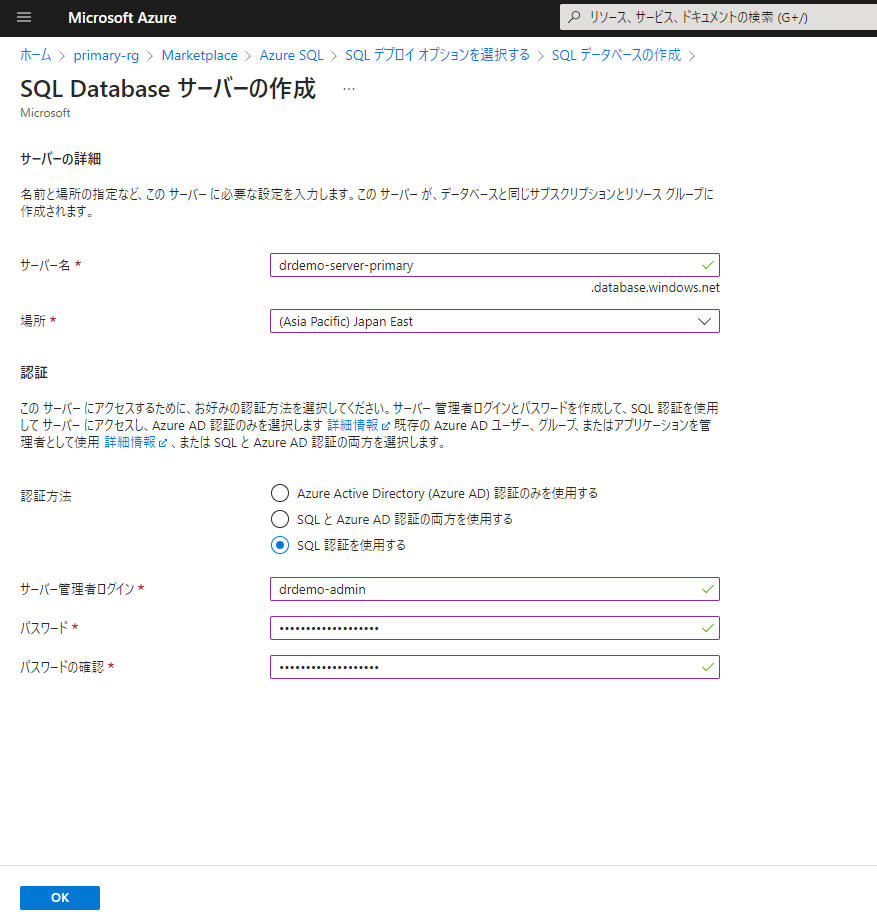
引き続きデータベースを作成します。
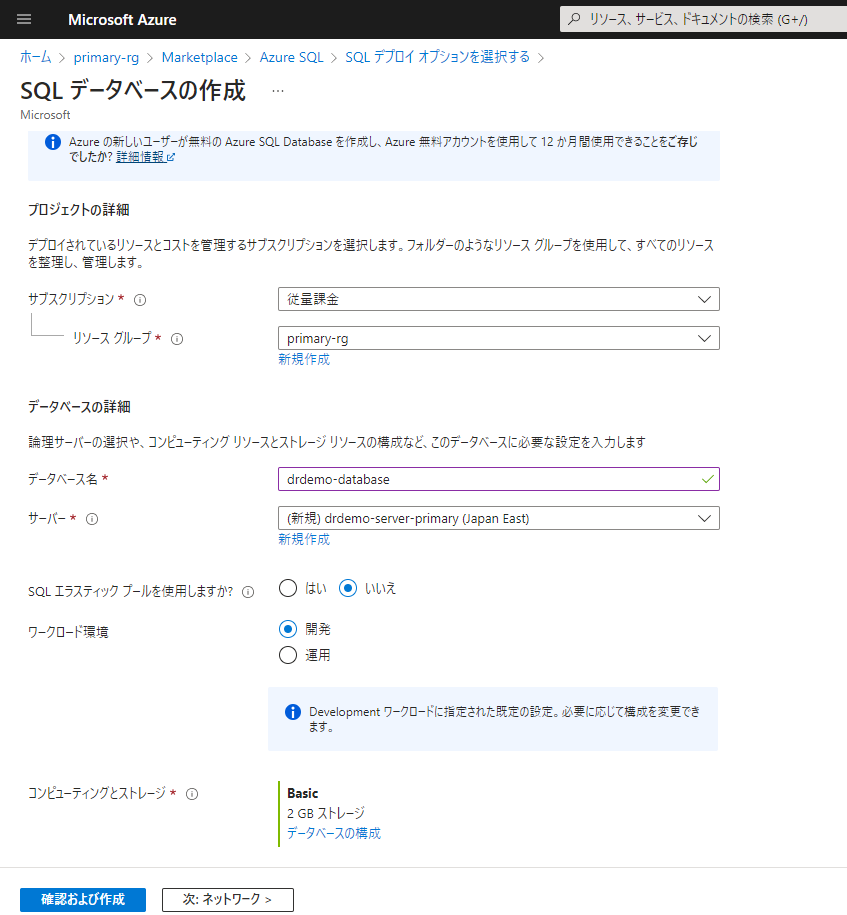
サーバー、データベースのデプロイが完了しました。
そうしたら、データベースに簡単なテーブルを作成しておきましょう。IdフィールドとNameフィールドのみ保持するUserテーブルを作成します。サーバーのファイアウォールルールにクライアントのIPアドレスを追加してあげるのを忘れずに。クエリエディターでサクッと作りました。

|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[User]( [Id] [int] IDENTITY(1,1) NOT NULL, [Name] [nvarchar](max) NULL, CONSTRAINT [PK_User] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO |
これでプライマリーリージョンのデータベースは完了です。次にセカンダリーリージョンに論理SQLサーバーを用意します。マーケットプレイスで「SQL server(logical server)」を選択します。
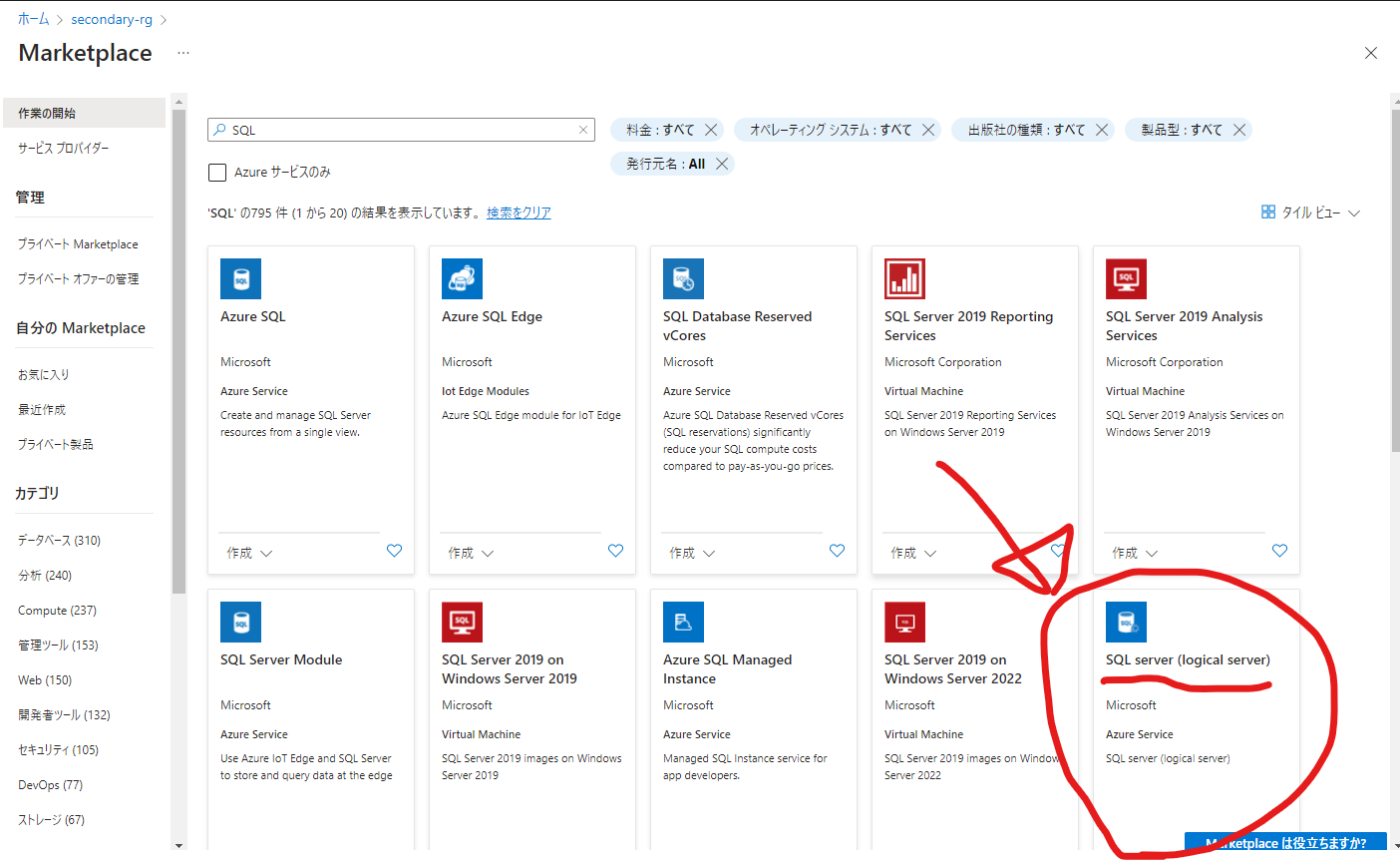
もう一度言います。SQL認証を利用するならプライマリーリージョンで作成した管理者ログインアカウントとパスワードと同じものをセカンダリーリージョンのSQLサーバーで入力して必ず一致させましょう。
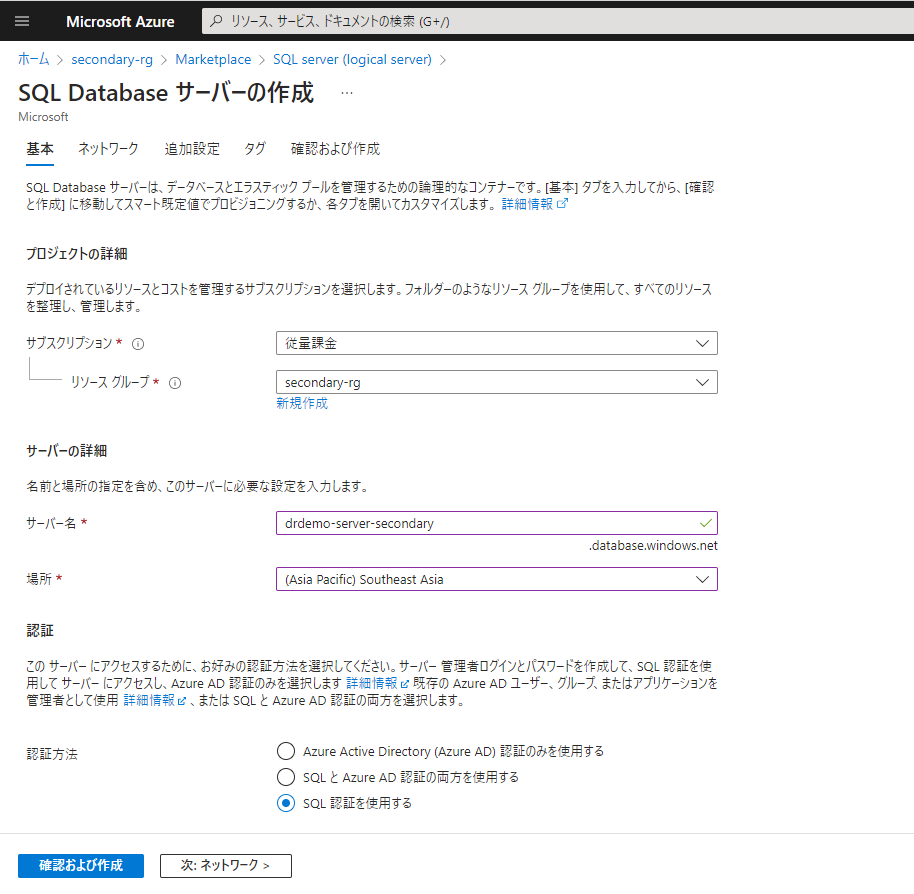
セカンダリーリージョンにサーバーのデプロイが完了しました。
次にフェールオーバーグループを設定して、データベースのGeoレプリケーションを可能にします。
プライマリーリージョンのAzure SQL Databaseサーバーを選択し、「フェールオーバーグループ」を選択します。

「グループの追加」をクリック。

「フェールオーバーグループ名」を入力し、サーバーにはセカンダリーリージョンのAzure SQL サーバーを選択します。その後、グループ内のデータベースで「データベースの構成」をクリックします。
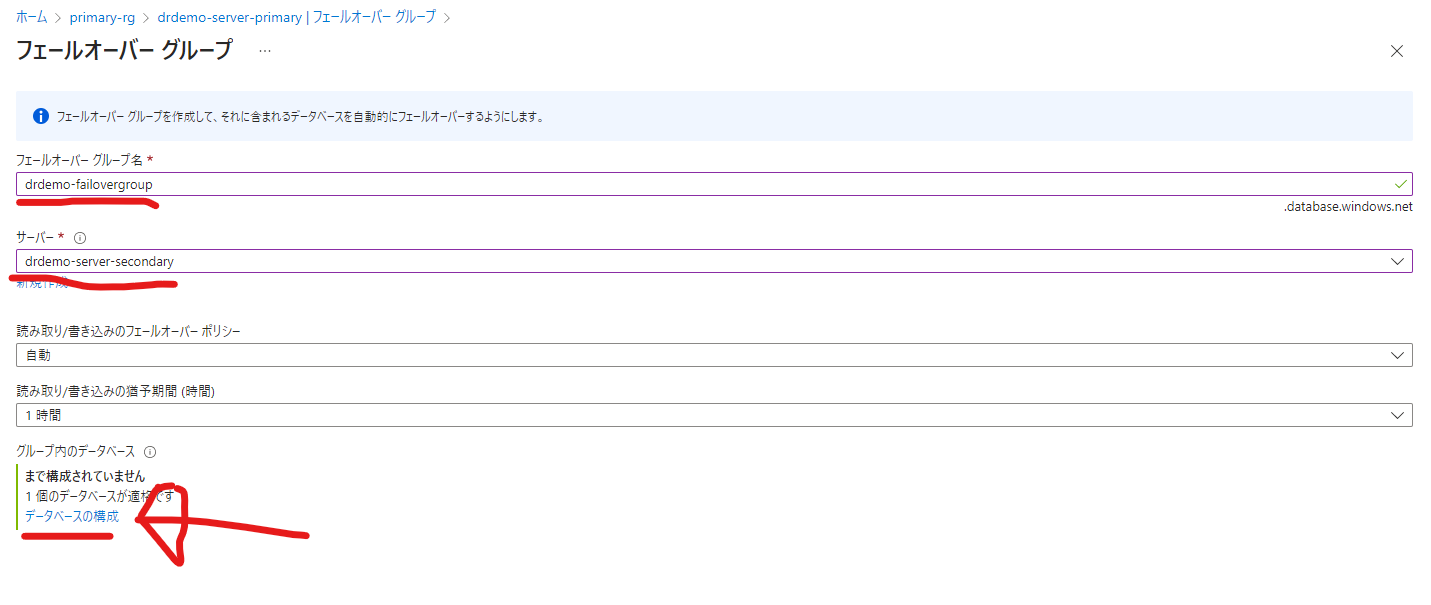
レプリケーション対象のデータベースにチェックをつけ「選択」をクリックしましょう。
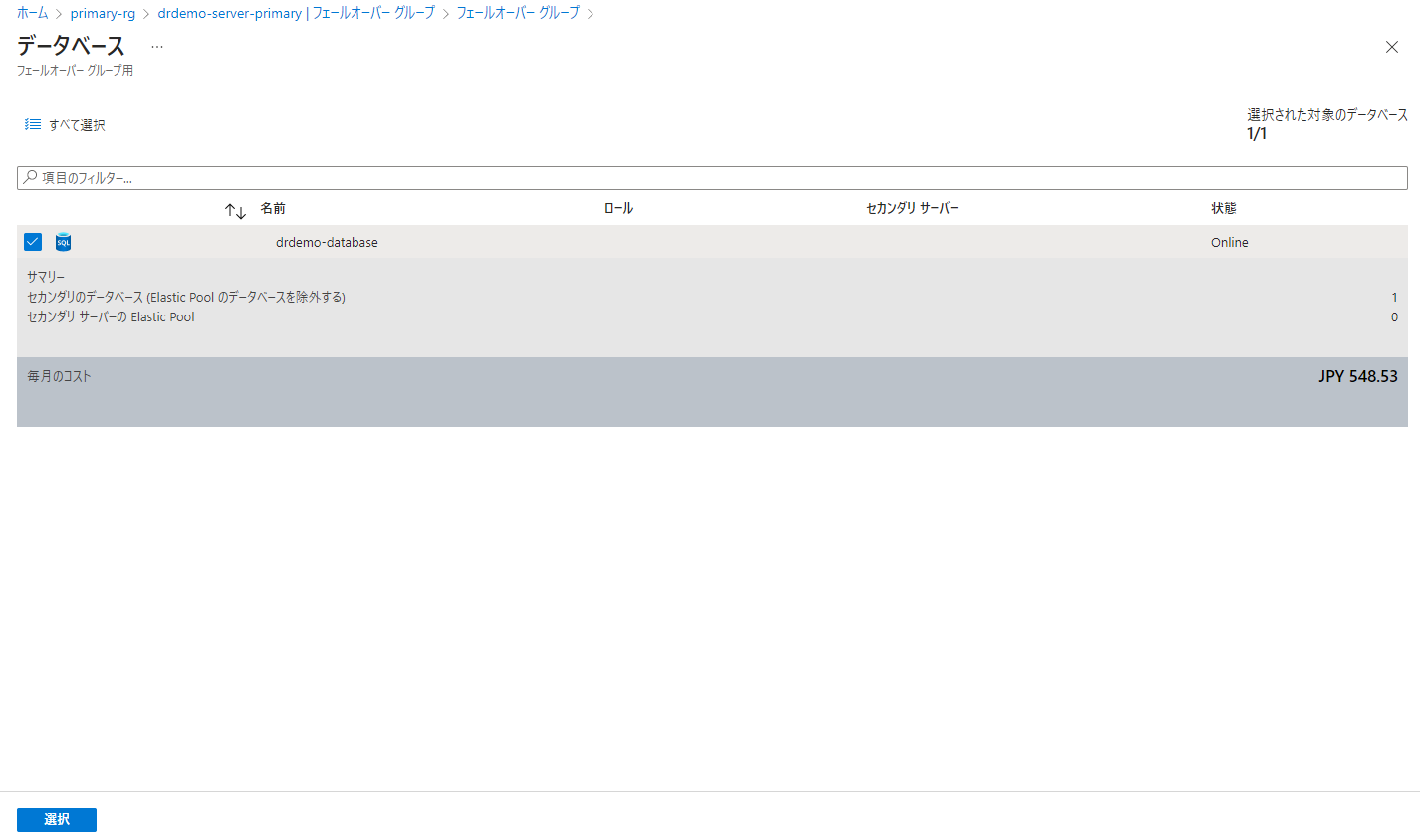
前の画面に戻り、「作成」をクリックするとフェールオーバーグループがデプロイされます。
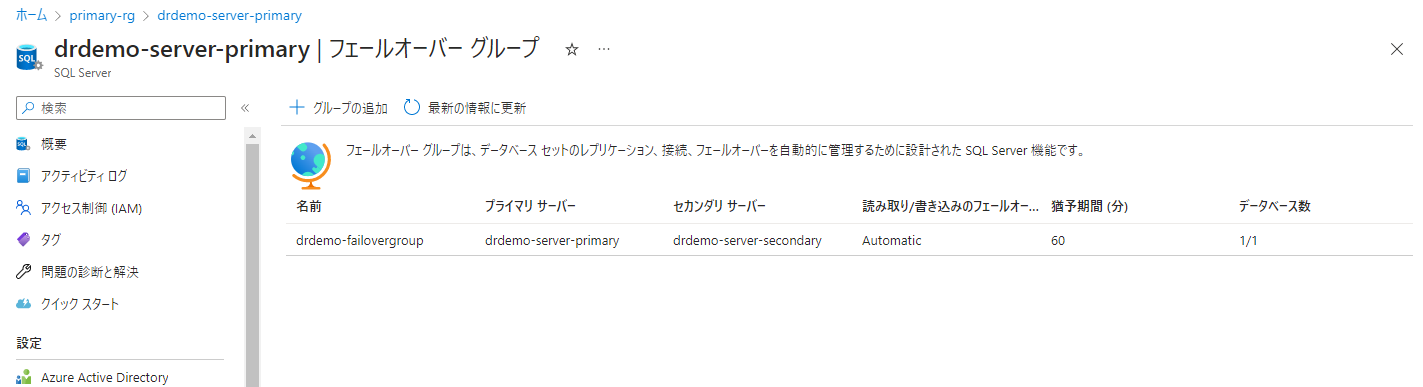
ちゃんとセカンダリーと同期しているのが確認できます。
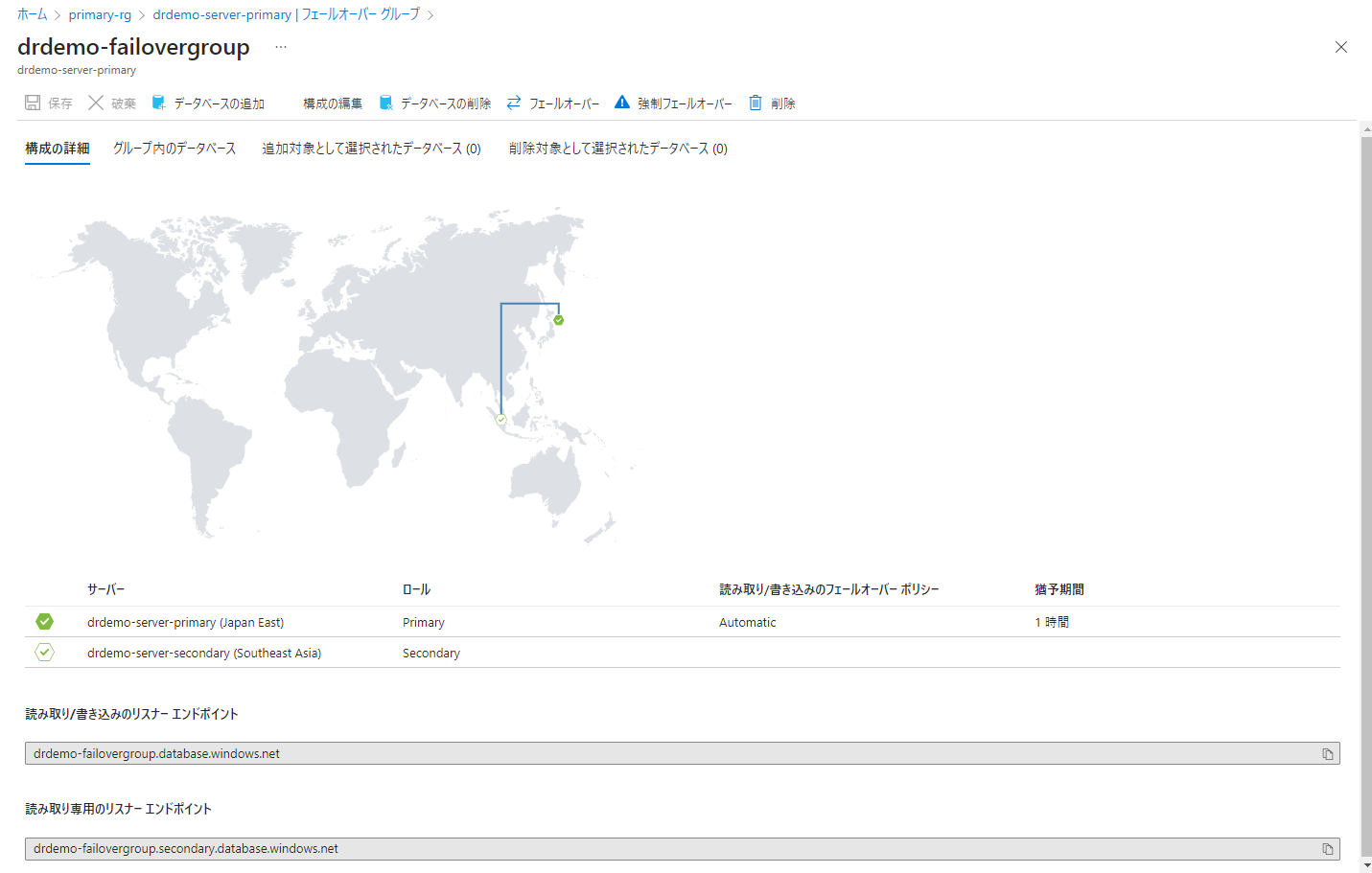
しばらくするとサーバーしか配置しなかったセカンダリーリージョンに、自動的にデータベースが同期されると思います。
SQL認証ではなく、マネージドIDを利用したAAD認証の場合は、以下の投稿をご参考に。SQL認証である必要はありませんので。
Azure Functionsの作成&コードのデプロイ
次にAzure Functionsを用意していきます。
プライマリー、セカンダリーそれぞれに作成していきますが、注意点です。この後、プライベートエンドポイントと仮想ネットワーク統合を行っていくのですが、その場合、AppServiceプランならBasic以上の価格プランが必要です。Premiumなら言うことなし。さらに、Traffic Managerとの連携も必要な場合、Standard以上である必要があります。ですので今回は「Standard S1」プラン一択でリソースを作っていきます。
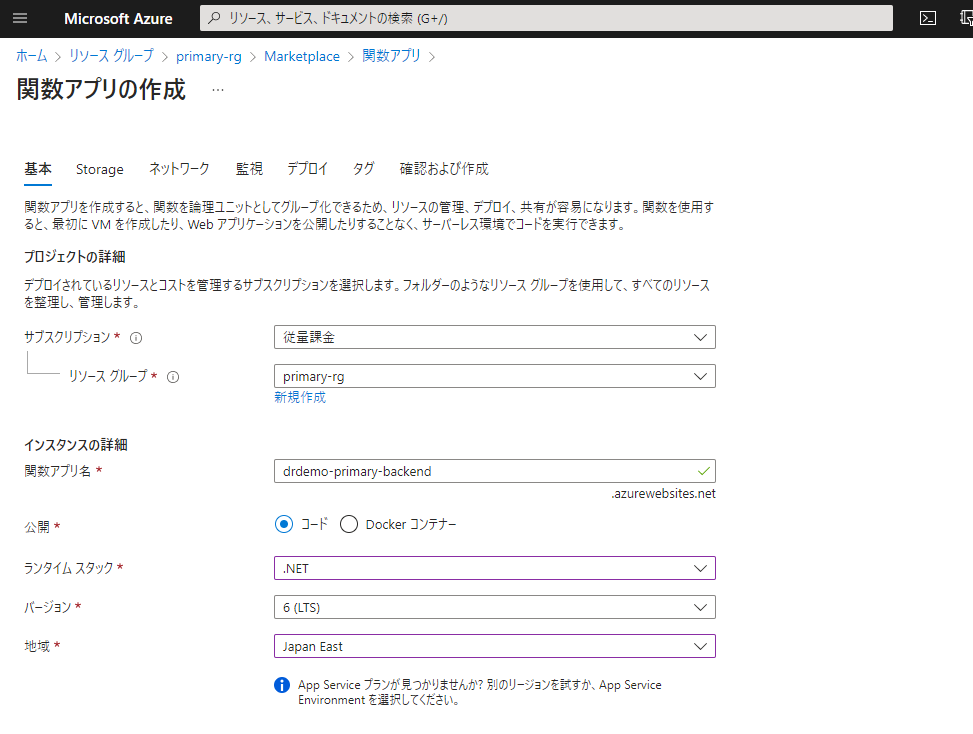
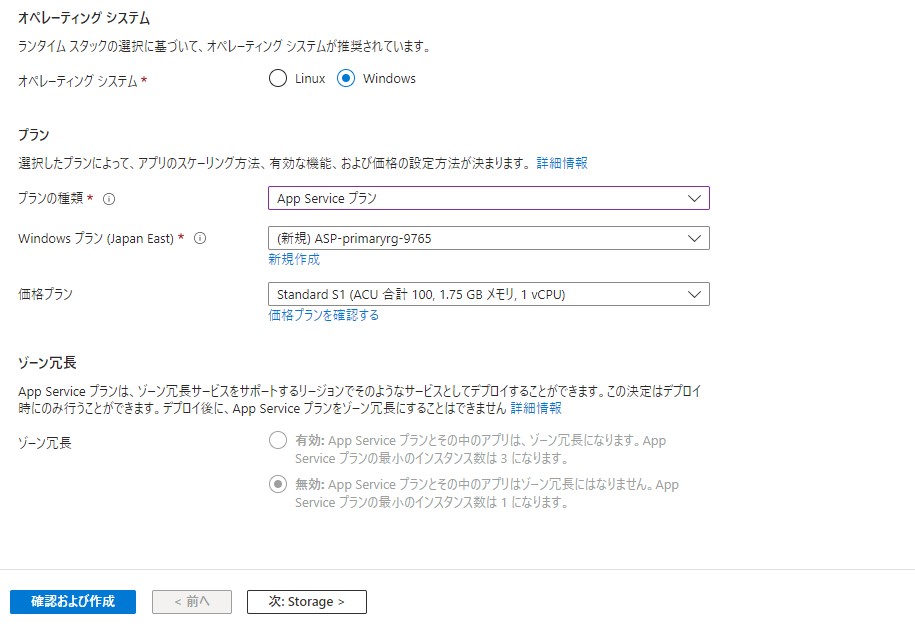
その他の構成は今のところなんでもOKです。
リソースのデプロイが完了したらソースコードを用意していきましょう。
コードは以前作成したEFCoreのコードファーストで作成したものを使ってみます。データベースにアクセスするコードがあればなんでもいいです。
以前の内容はこちらから。
今回使うコードは以下のような感じです。HTTPリクエストからnameパラメーターを受け取り、データベースのUserテーブルにIDを採番して新規登録するコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
using System; using System.IO; using System.Linq; using System.Threading.Tasks; using Microsoft.AspNetCore.Mvc; using Microsoft.Azure.WebJobs; using Microsoft.Azure.WebJobs.Extensions.Http; using Microsoft.AspNetCore.Http; using Microsoft.Extensions.Logging; using CodeFirstExampleFunctionApp.Models; namespace CodeFirstExampleFunctionApp { public class Function1 { private readonly MyContext dbContext; public Function1(MyContext context) { dbContext = context; } [FunctionName("Function1")] public async Task<IActionResult> Run( [HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = null)] HttpRequest req, ILogger log) { log.LogInformation("C# HTTP trigger function processed a request."); string name = req.Query["name"]; await dbContext.AddAsync(new User() { Name = name }); await dbContext.SaveChangesAsync(); // 自動採番された最後のIDを取得する int id = dbContext.User.Max(x => x.Id); return new OkObjectResult($"ユーザーを登録しました。ID={id}、ユーザー名={name}"); } } } |
コードができたら、プライマリー、セカンダリーの両リージョンのAzure Functionsにデプロイします。今回はパイプラインは組まず、VisualStudioから手動でデプロイします。二つのリージョンのAzure Functionsリソースにデプロイするのを忘れずに。
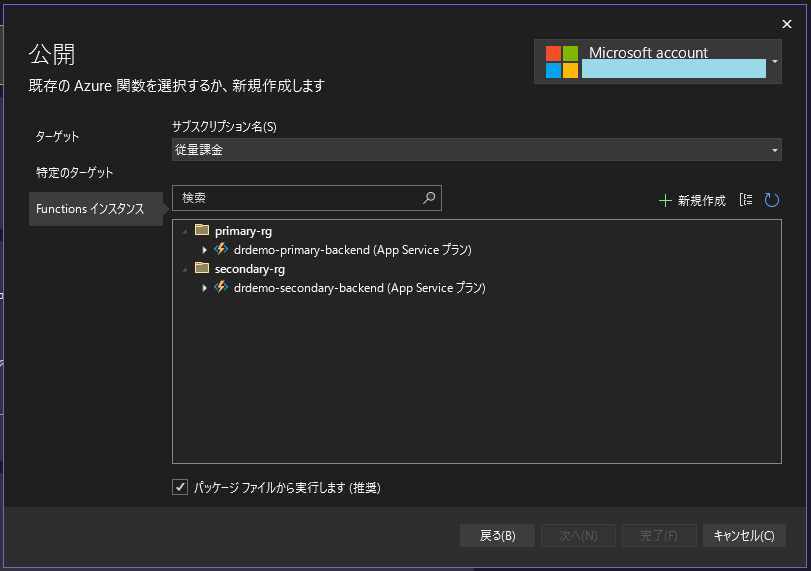
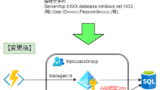
最後に、前の手順で作成したフェールオーバーグループの「読み取り/書き込みのリスナーエンドポイント」をデータベースアクセスの接続文字列として設定しておきましょう。
通常のデータベース接続文字列は
|
1 |
Server=tcp:drdemo-server-primary.database.windows.net,1433;Initial Catalog=drdemo-database;Persist Security Info=False;User ID=drdemo-admin;Password={your_password};MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30; |
ですが、フェールオーバーグループを設定し、フェールオーバー後もアプリケーションに保持した接続文字列を変更せずにデータベースにアクセスするには以下のように接続文字列を設定します。
|
1 |
Server=tcp:drdemo-failovergroup.database.windows.net,1433;Initial Catalog=drdemo-database;Persist Security Info=False;User ID=drdemo-admin;Password={your_password};MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30; |
違いは、Server指定の場所ですね。ここにフェールオーバーグループの「読み込み/書き込みのリスナーエンドポイント」を設定します。ちなみにこのフェールオーバーグループのドメイン名(=読み込み/書き込みのリスナーエンドポイント)、「どこにあるの?」って話ですが、Azure SQL Databaseサーバーのフェールオーバーグループ設定内の以下のページの下部にあります。どこにあったか忘れてなかなか躓きます。
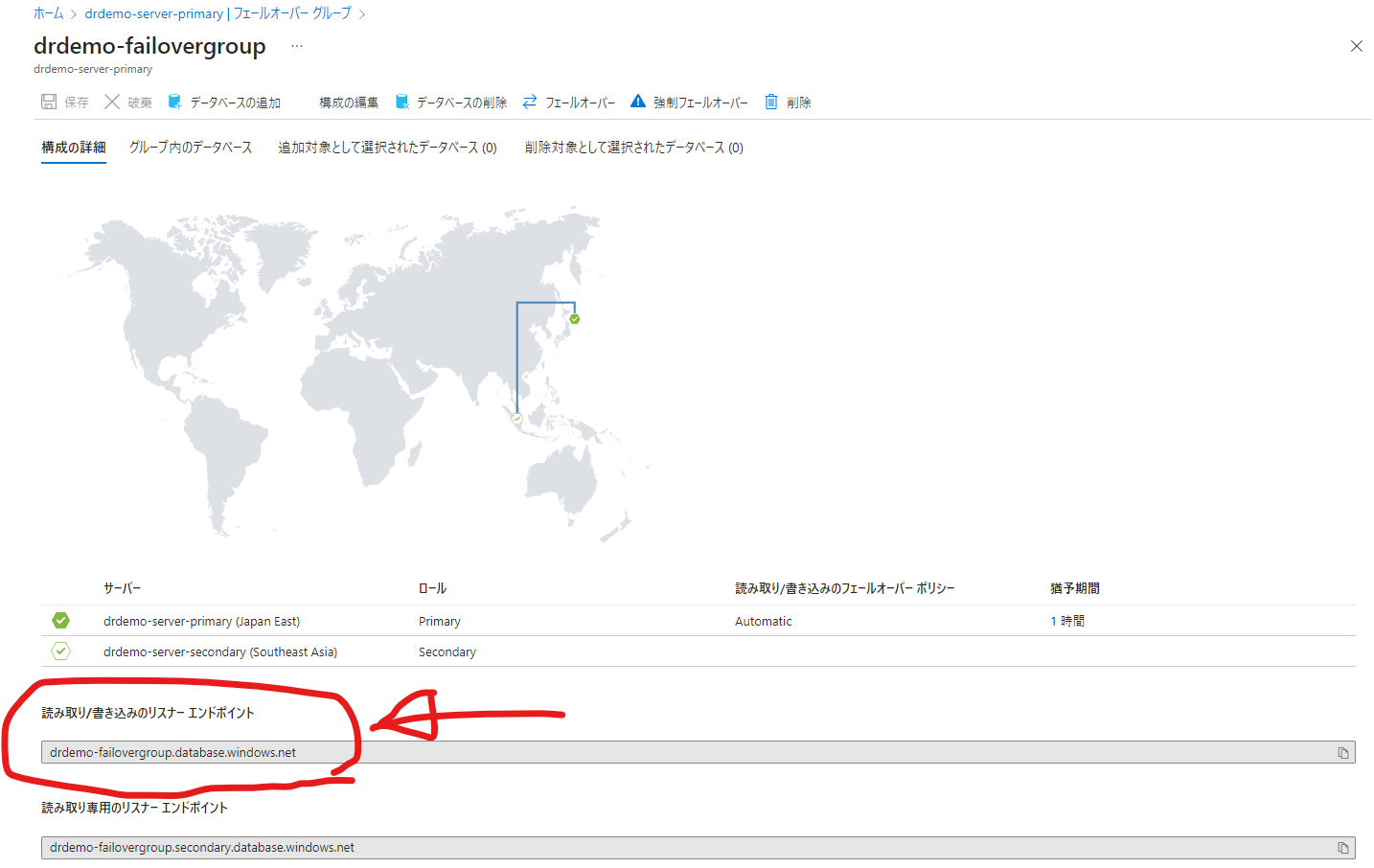
これをAzure Functionsのアプリケーション設定に値として設定してあげましょう。プライマリーAzure FunctionsもセカンダリーAzure Functionsも同じ値で設定してください。そうすることでAzure SQLでフェールオーバーが発生してもAzure Functions側では接続文字列の変更を行うことなく、アクティブなデータベースにアクセスできます。
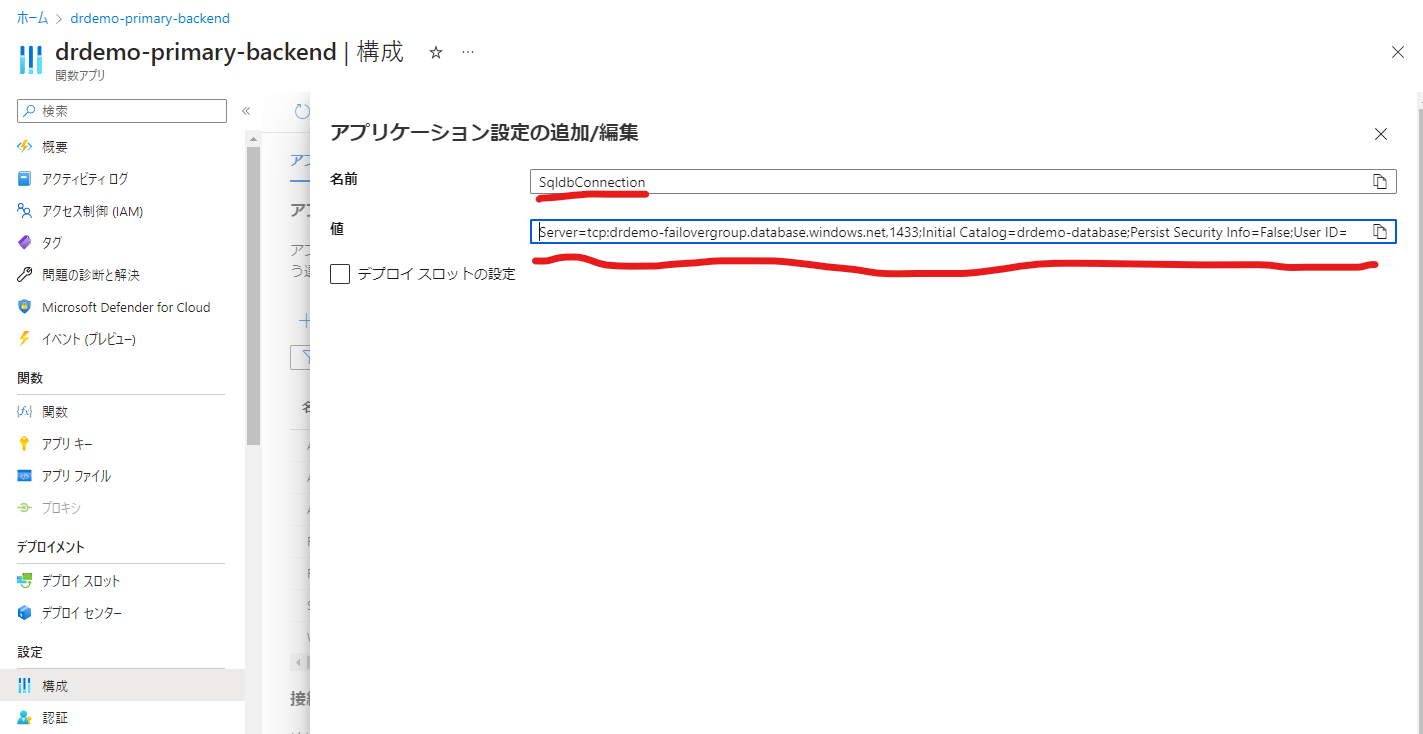
仮想ネットワーク、プライベートリンク、グローバルVNetピアリングの設定
この時点でAzure SQL DatabaseのファイアウォールルールにAuzre FunctionsのIPアドレスを設定して、リクエストを投げればデータベースに書き込まれると思います。余裕がある方は試してみては。
ひとまず、ここでは仮想ネットワーク(VNet)を構築し、データベースへのパブリックアクセスを無効化します。
プライマリーリージョンにVNetを構築します。(セカンダリーもIPが変わるくらいで手順は一緒です。)
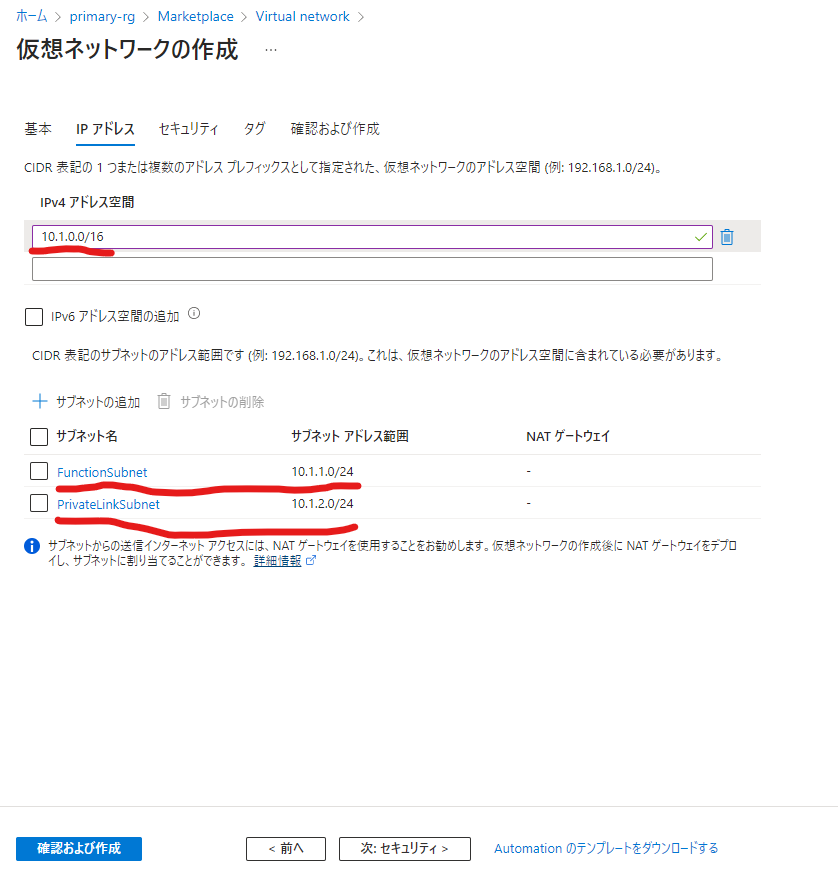
次にAzure SQL Databaseのサーバーにアクセスしてプライベートエンドポイントを作成していきます。作成したプライベートエンドポイントを先ほど作成したPrivateLinkSubnetに紐づけることでそのサブネットからのみデータベースにアクセス可能になります。
ネットワークを選択し、「プライベートアクセス」-「+プライベートエンドポイントを作成します」を選択します。
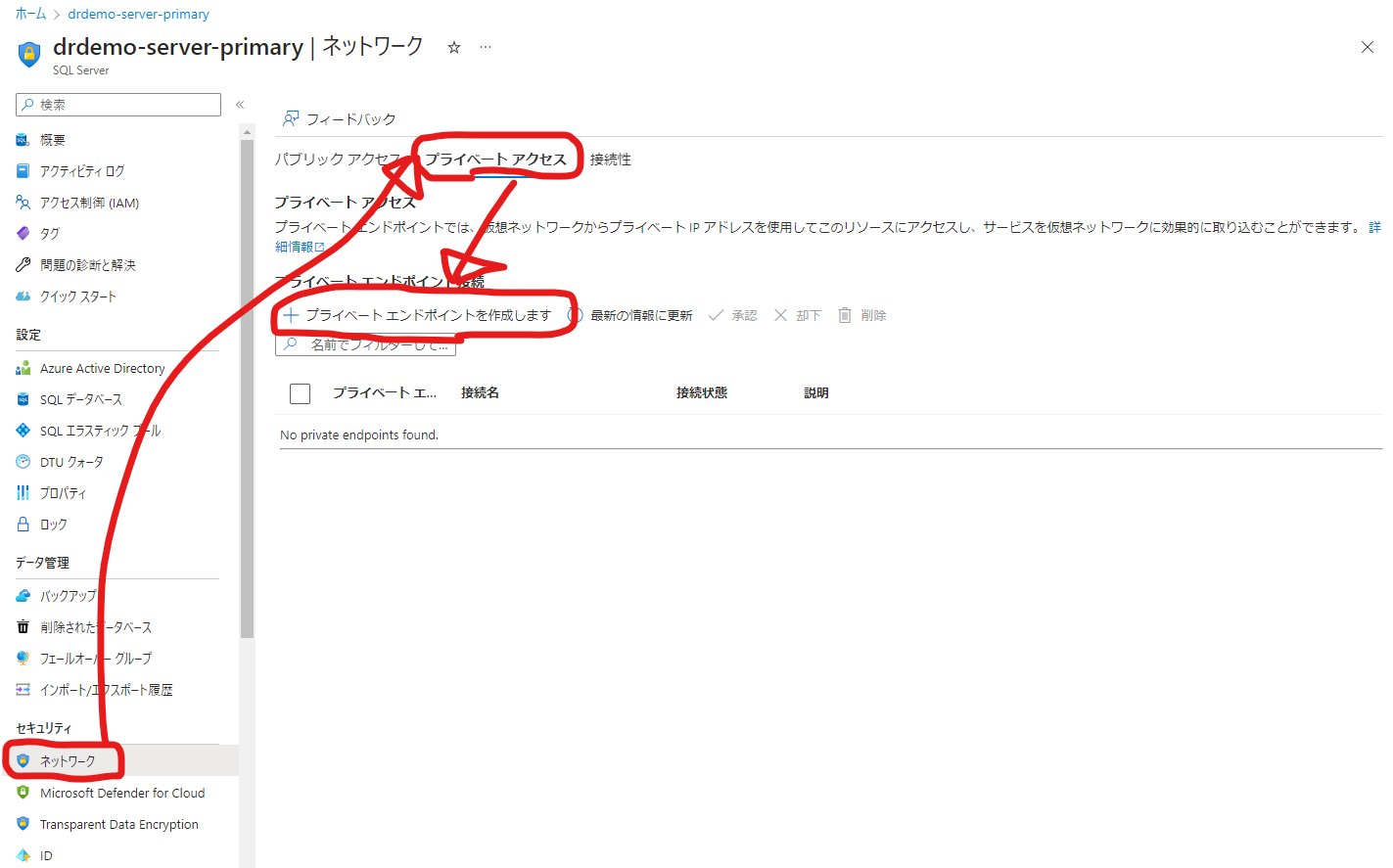
名前を指定します。
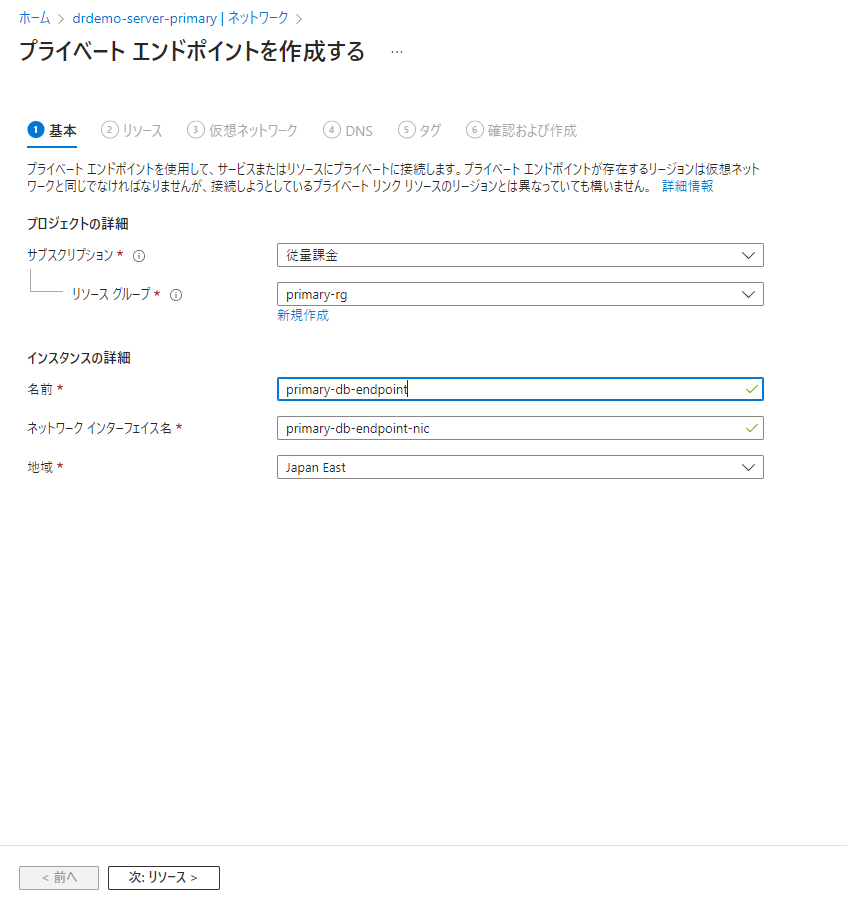
自動的に対象サブリソースに「sqlServer」が設定されていると思います。
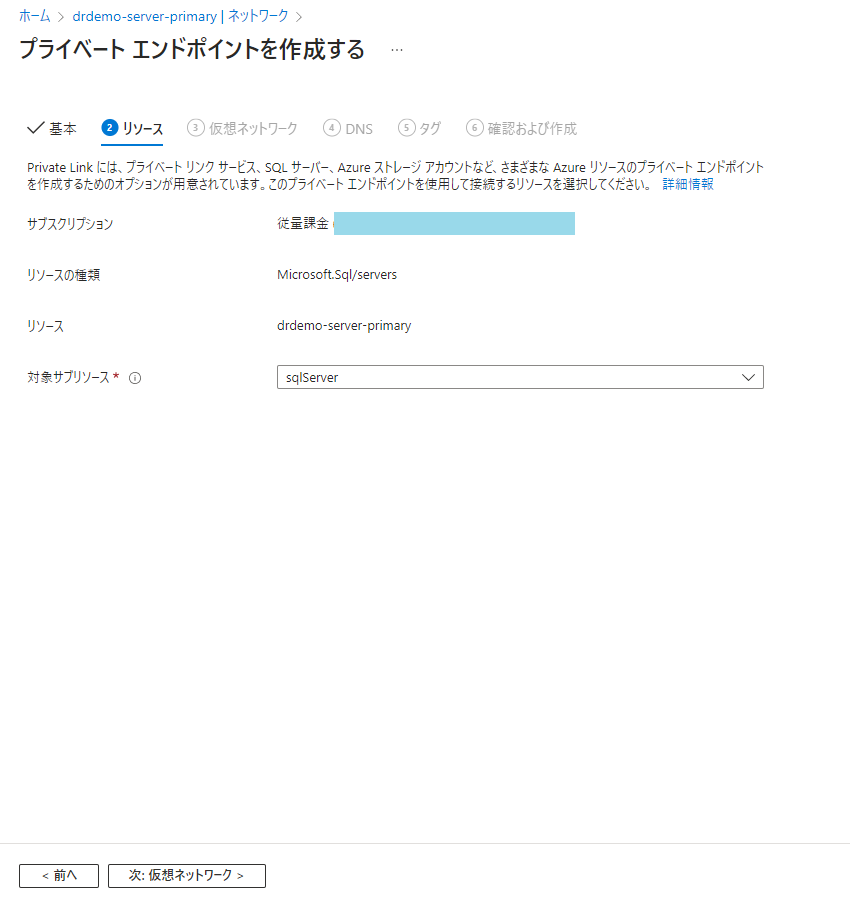
どのサブネットに配置するかを指定しましょう。今回は構成図の通りVNet作成時に追加したPrivateLinkSubnetに配置します。以外はデフォルトでOK。
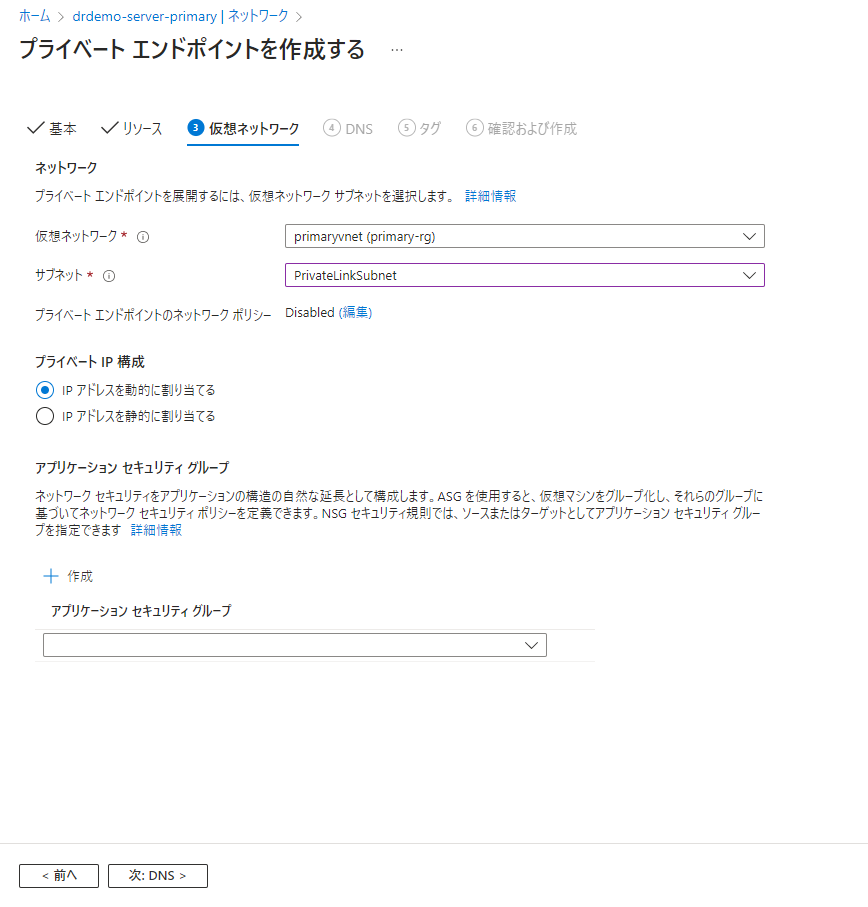
自動的にプライベートDNSを構成してくれます。そのまま次へ。タグもそのまま次で「作成」を行いましょう。
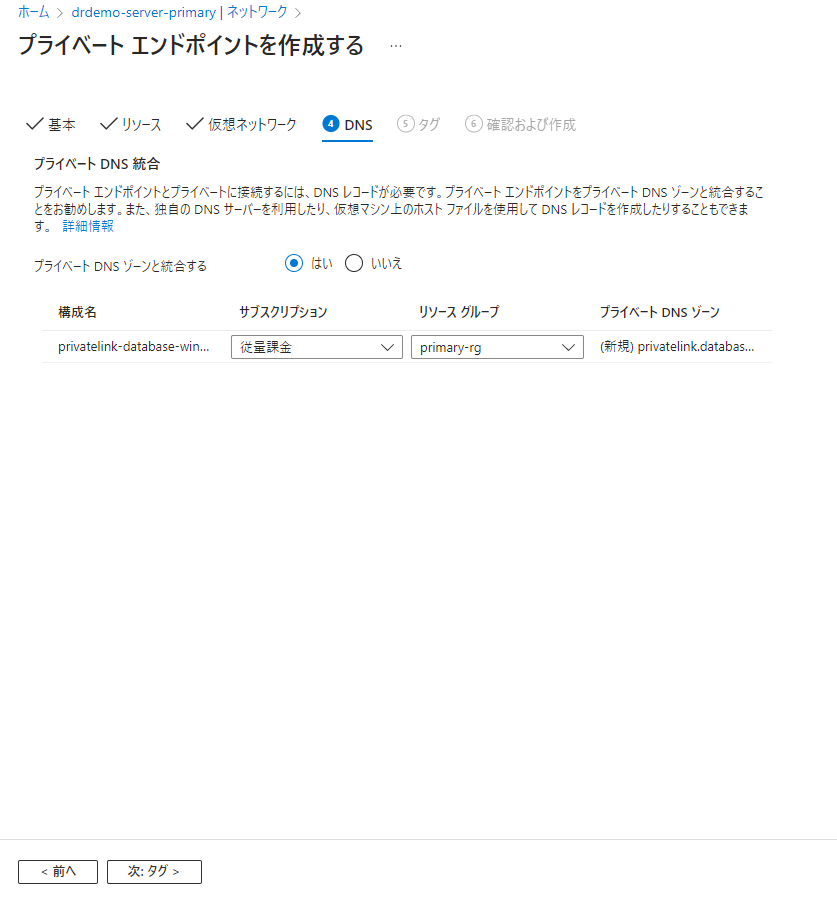
プライベートエンドポイントがデプロイされました。
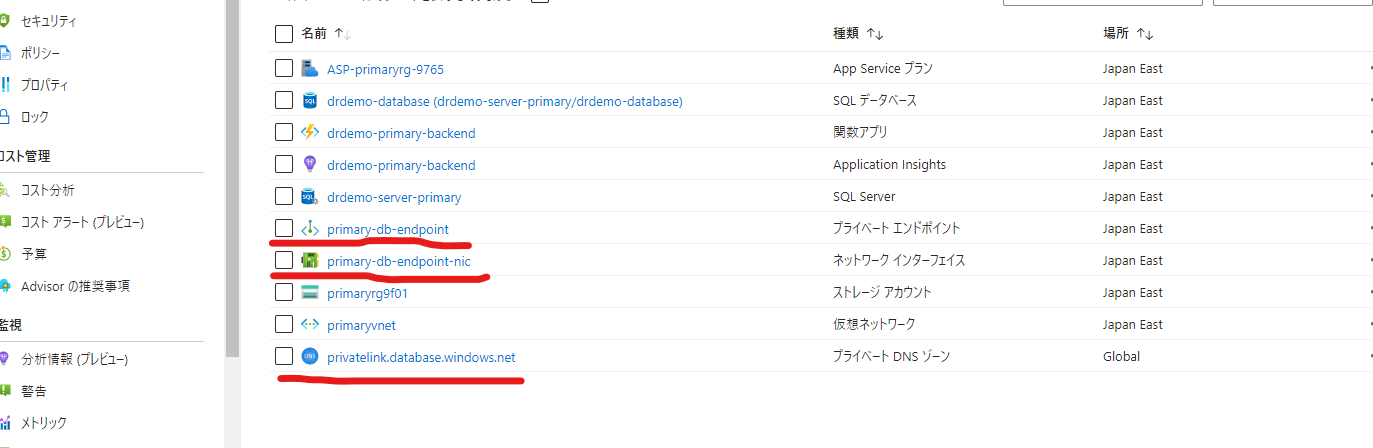
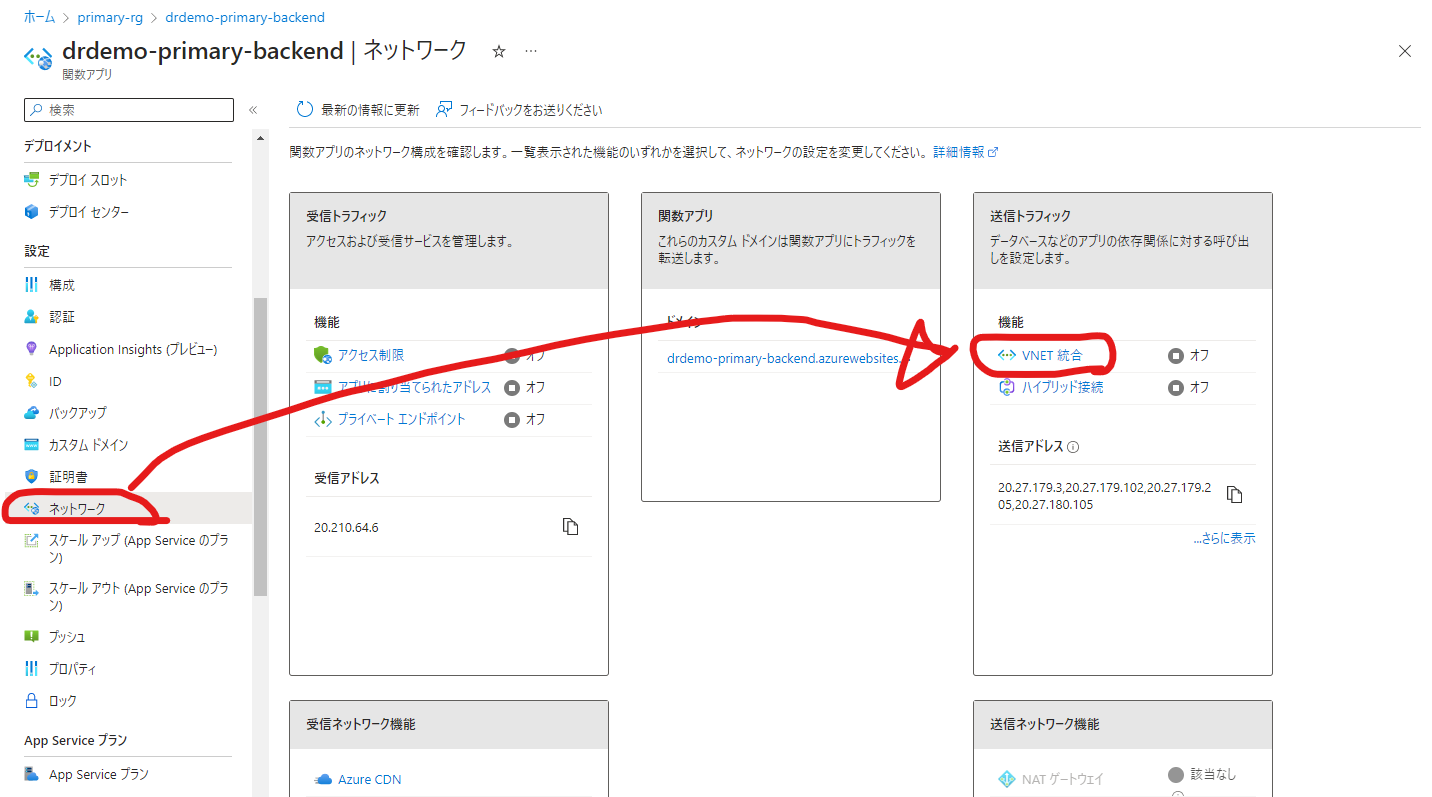
次にAzure FunctionsのVNET統合を行っていきます。
Azure Functionsにアクセスし、ネットワークから送信トラフィックの「VNET統合」をクリックします。
「VNetの追加」をクリックし、仮想ネットワーク、サブネットを指定してOKをクリックしましょう。
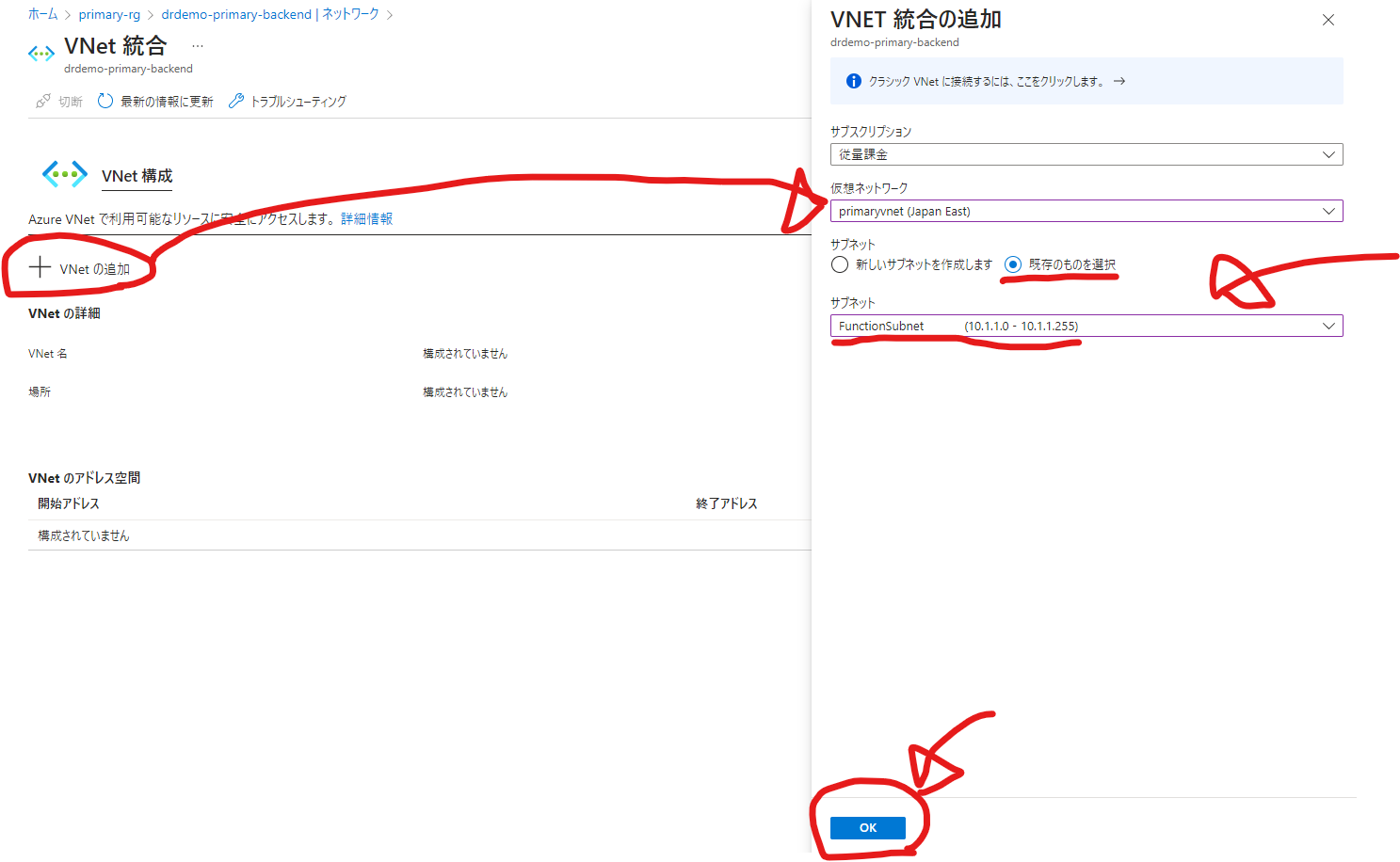
これでAzure FunctionsからVNET内へアクセスすることができます。
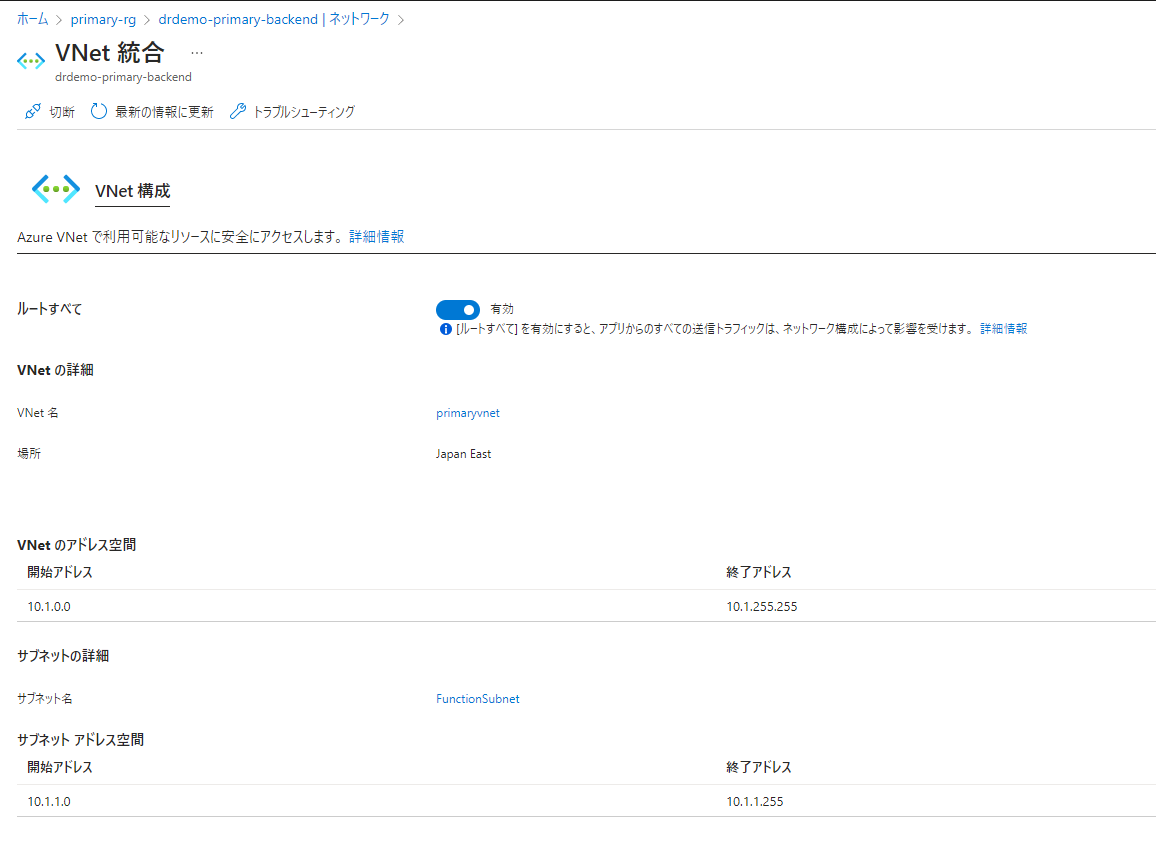
プライベートリンクの設定の最後にAzure SQL Databaseのファイアウォールルールを変更しましょう。パブリックアクセスを「無効にする」を選択することでデータベースへのアクセスをVNET統合したAzure Functionsのみに制限することができます。
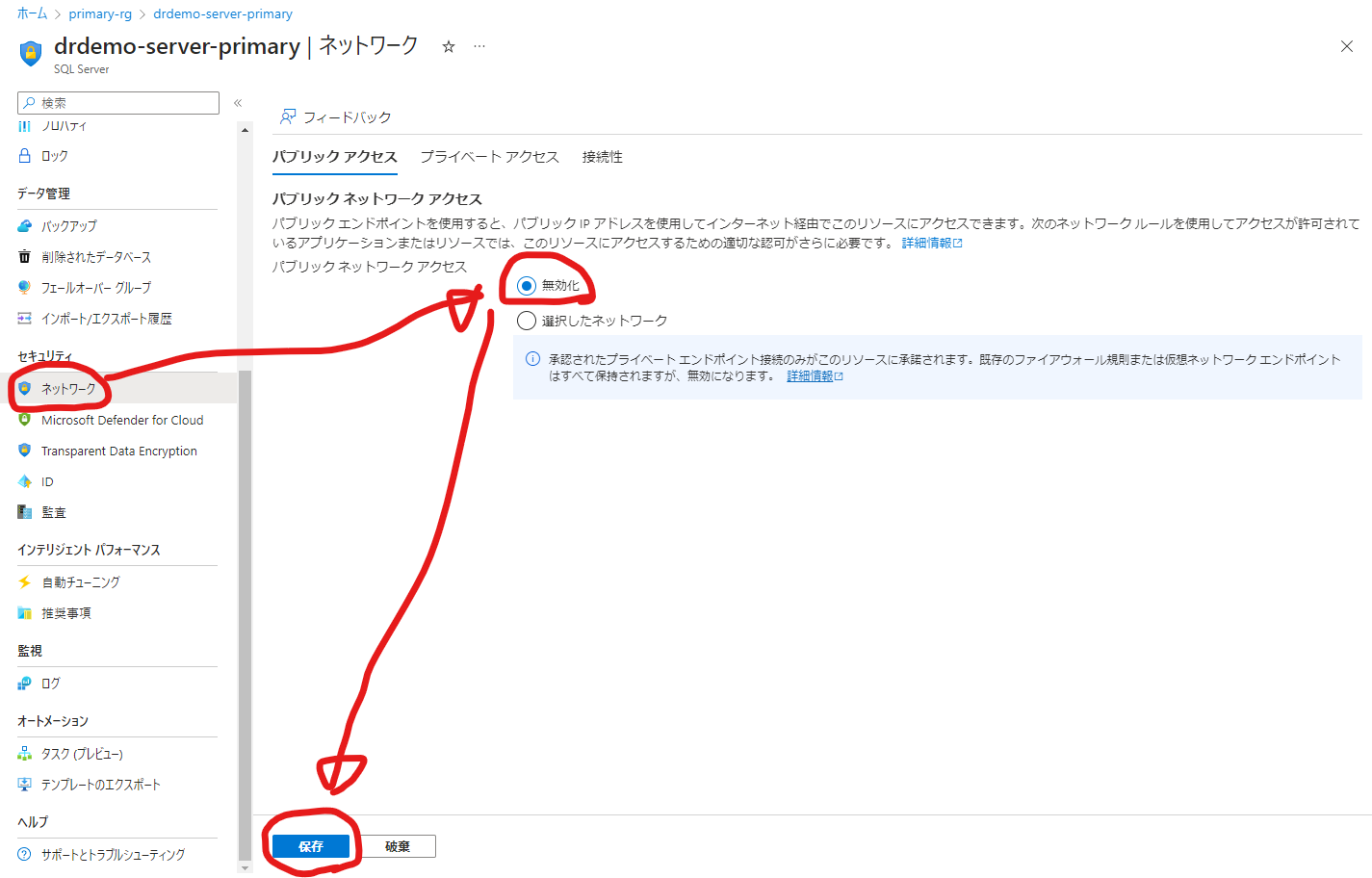
VNET、プライベートリンク、VNET統合の設定がプライマリーもセカンダリーも終わり、パブリックアクセスを無効化した環境ができたら、次に仮想ネットワークピアリングを設定していきます。VNETピアリング、ここでは、リージョンをまたいだVNET同士の通信を可能にしますので、グローバルVNETピアリングを設定していきます。これによりプライマリーリージョンとセカンダリーリージョンでフェールオーバーが発生してもアクティブなデータベースへのアクセスを可能にします。
プライマリーリージョンに設定した仮想ネットワークにアクセスし、「ピアリング」を選択します。「追加」をクリックしてください。
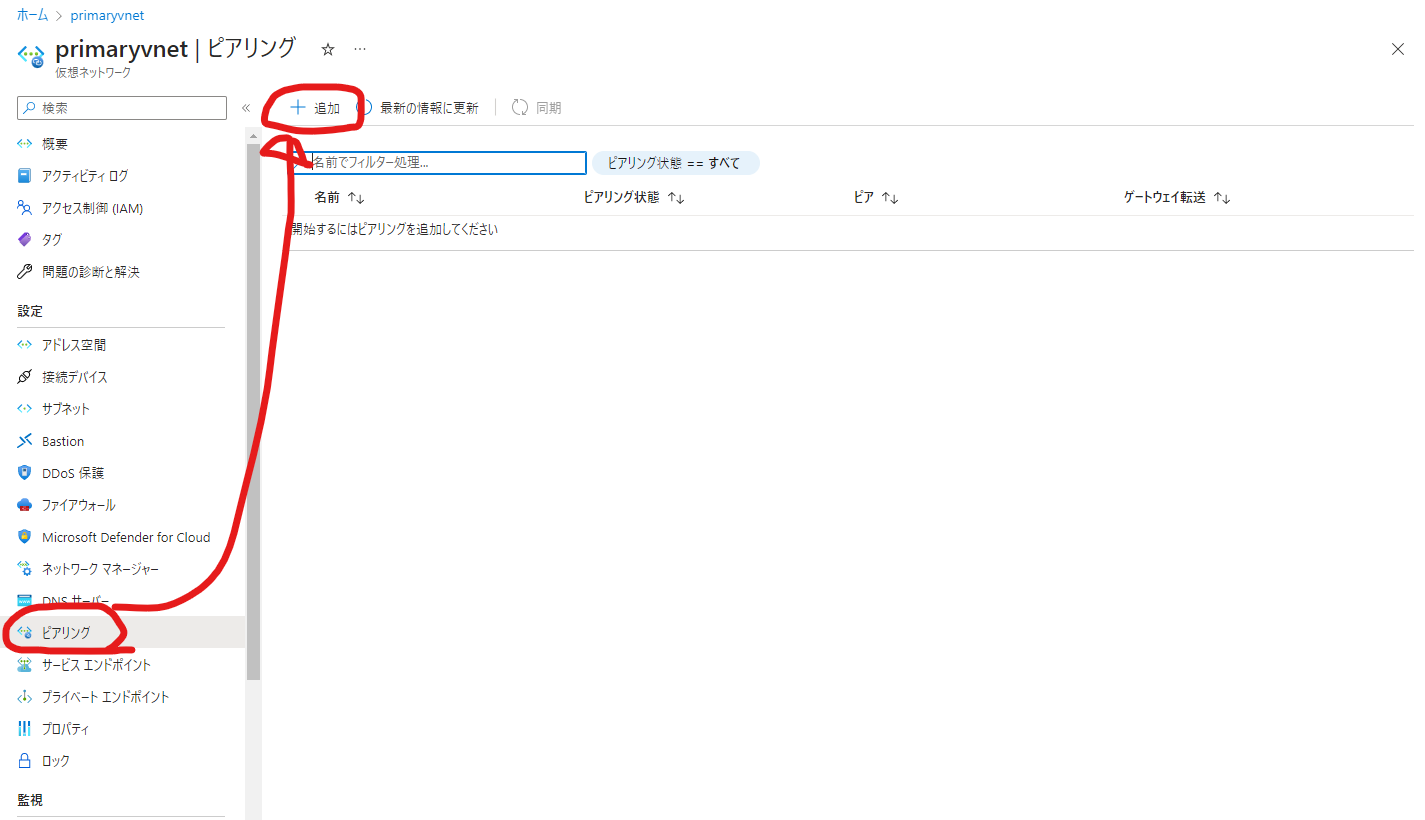
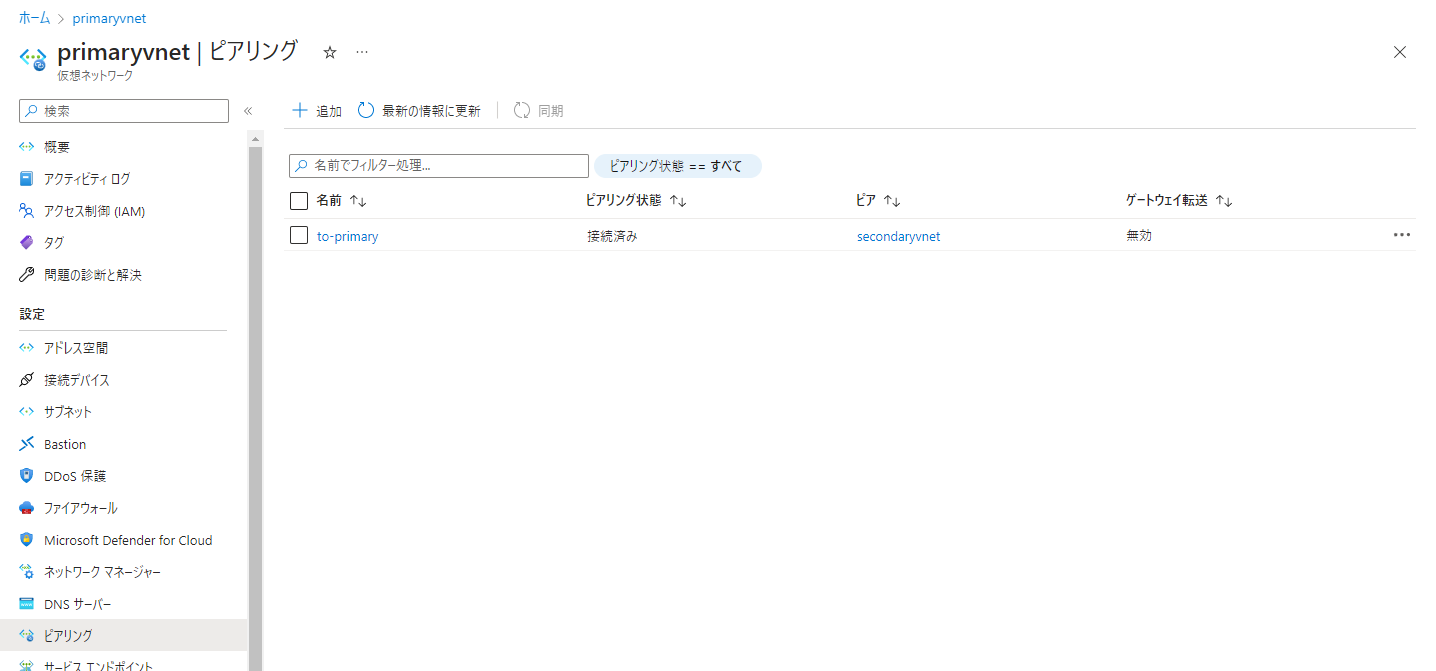
以下のようにピアリングを設定します。要はお互いのVNETを指定するだけです。
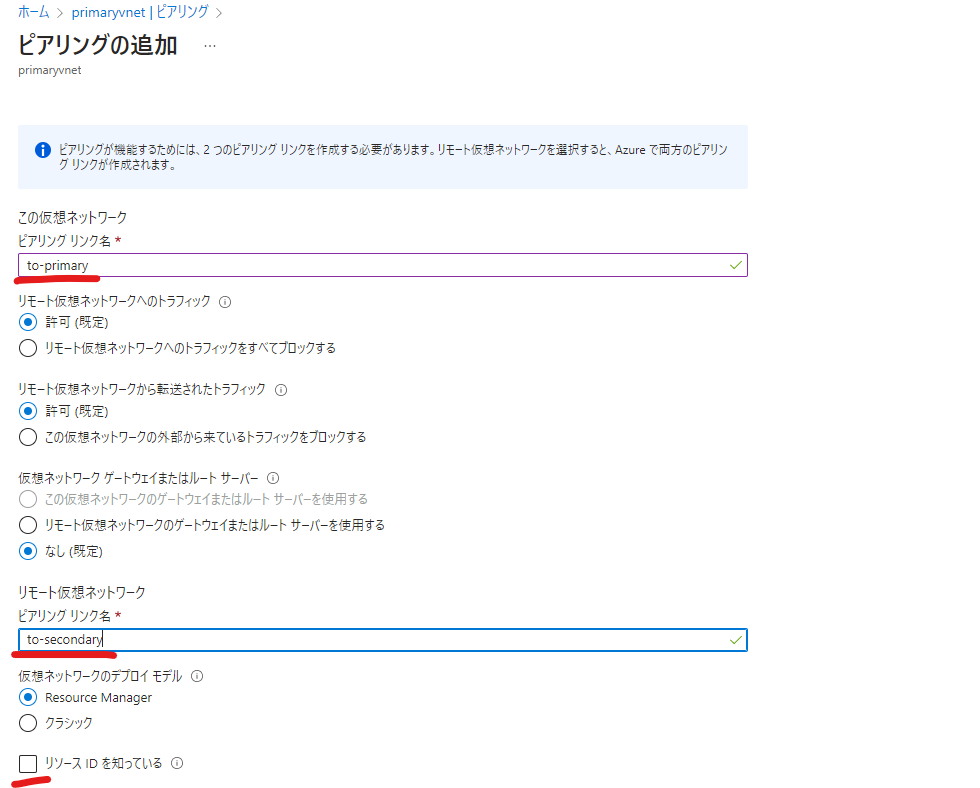
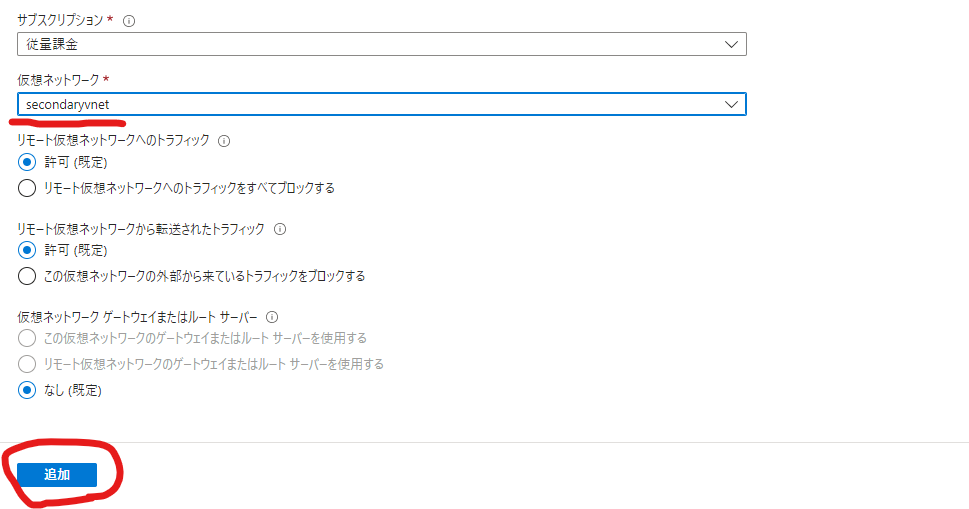
これでリージョン間のVNET同士が通信できるようになったので、フェールオーバーが発生しても相互にアクセスが可能な状態になります。
この段階でほぼほぼDR環境は出来上がっているのですが、Azure SQLをフェールオーバーさせてバックエンドAzure Functionsからリクエストを投げると「Failed to update database “データベース名” because the database is read-only.」というメッセージ出して落ちます。これに対処するためにもう一工夫必要です。
プライベートDNSゾーンにプライマリー、セカンダリーの各データベースのプライベートリンクIPアドレス設定を追加します。
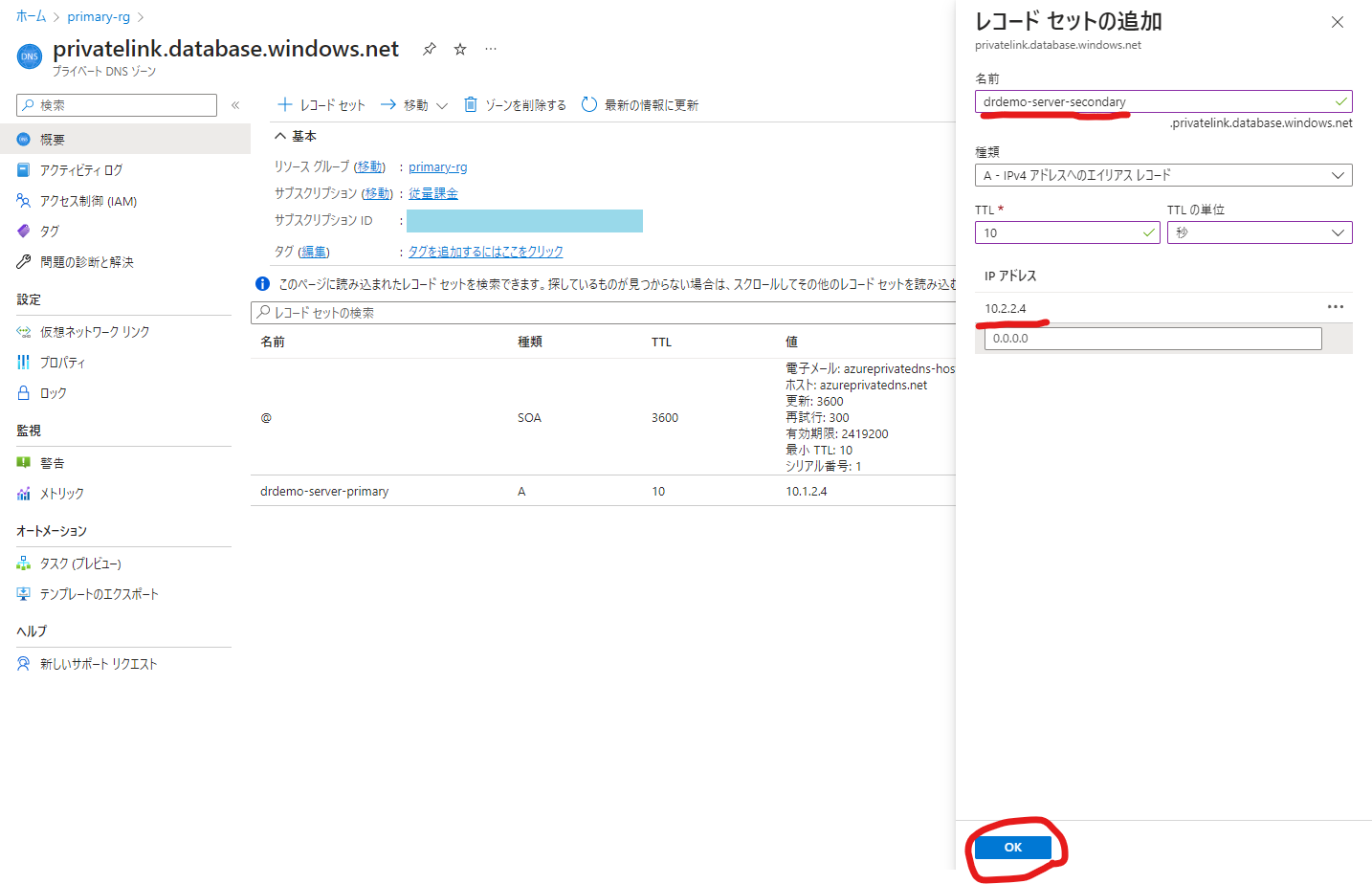
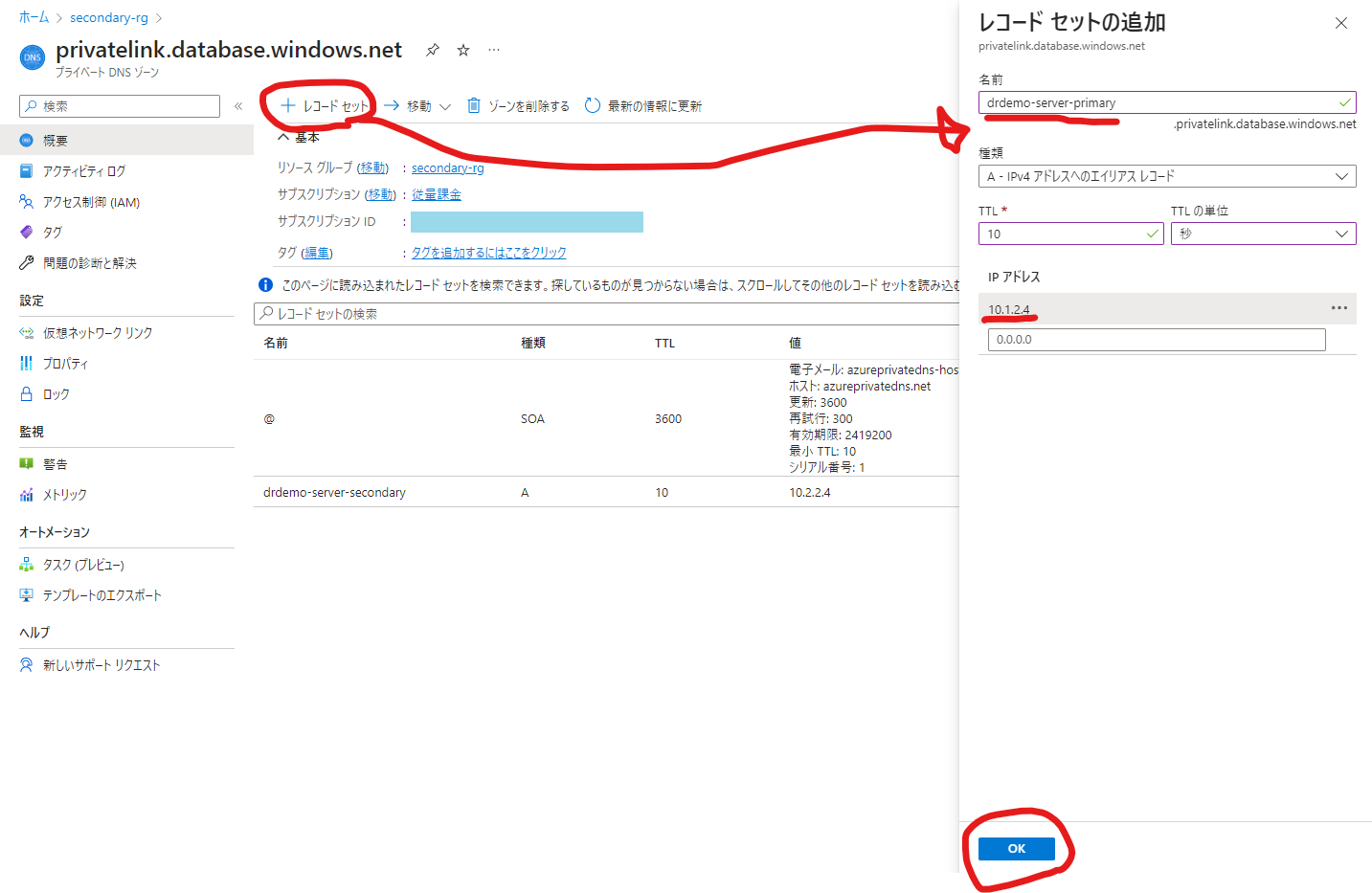
SQLをフェールオーバーさせます。
Azure Functionsにアクセスするとフェールオーバーしても、無事データベースにアクセスできたのが確認できました。

Azure Traffic Managerでのエンドポイント切り替え
疲れましたね。ここまで書いてて自分でも分割すればよかったって後悔してます。が、これで最後の手順です。
Traffic Managerを設定して、バックエンドAzure Functionsのリクエスト先を切り替えられるようにしましょう。これにより、プライマリーリージョン自体の災害時にセカンダリーリージョンのAzure Functionsやその先のデータベース、ストレージを利用したままサービスを継続できる?のではないでしょうか。
Traffic Managerプロファイルを追加します。
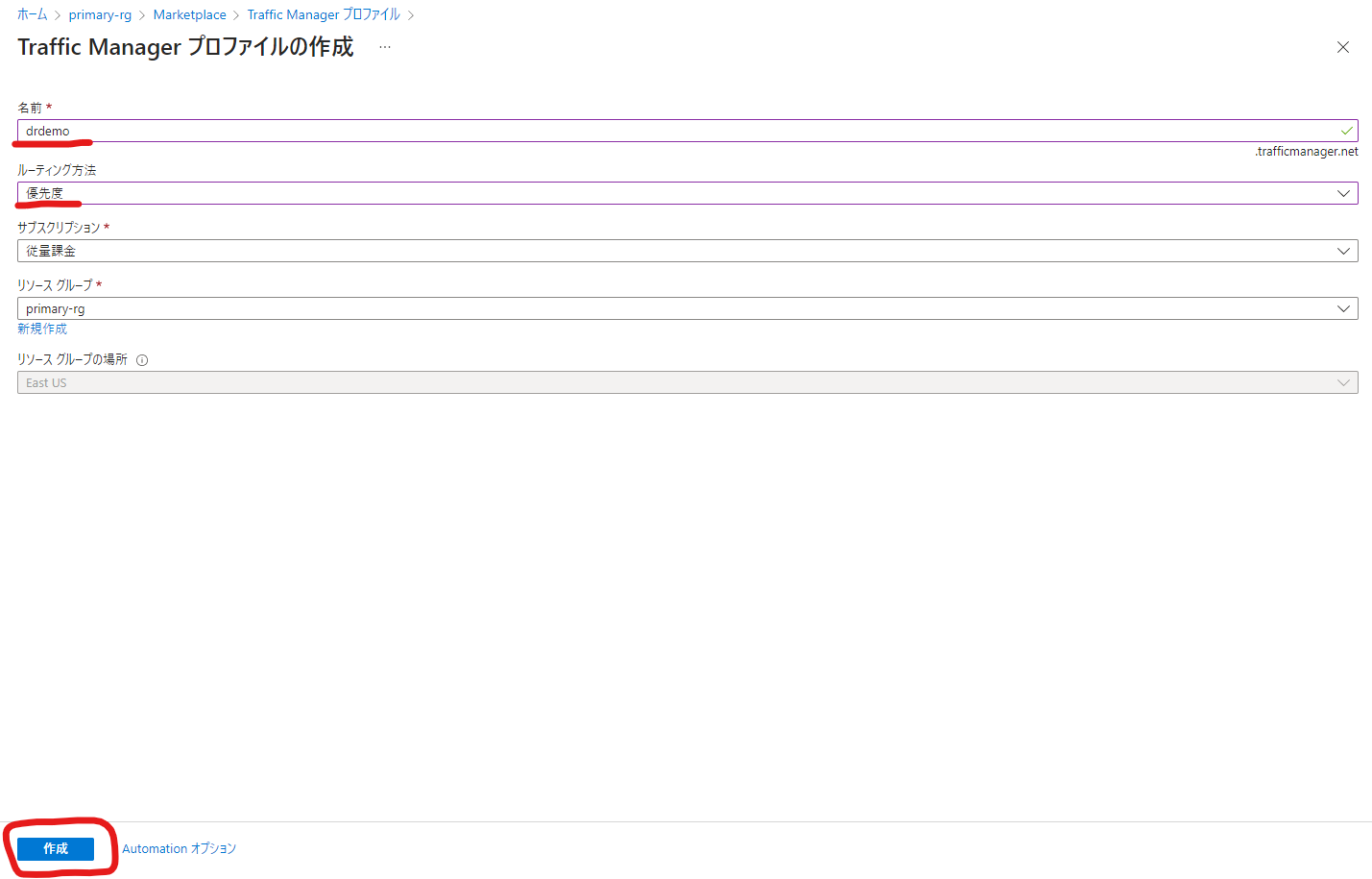
名前を設定し、ルーティング方法に「優先度」を設定して「作成」をクリックしましょう。
Traffic Managerリソースに移動し、エンドポイントを選択し、「追加」をクリックします。
エンドポイントの追加画面でまずはプライマリーリージョンに振り分けるエンドポイント設定を行っていきます。特に種類は「Azureエンドポイント」、ターゲットリソースの種類は「App Service」、ターゲットリソースにプライマリーリージョンのAzure Functionsバックエンドリソース名を指定します。そして、優先度に「1」を設定しましょう。優先度は値が小さいほど優先して実行されるエンドポイントになります。優先度1のエンドポイントの正常性が担保できないとTraffic Managerにより判断された場合は、その次の優先度の値のエンドポイントにトラフィックが振り分けられます。
同様に、セカンダリーリージョンに振り分けるエンドポイントも設定しましょう。
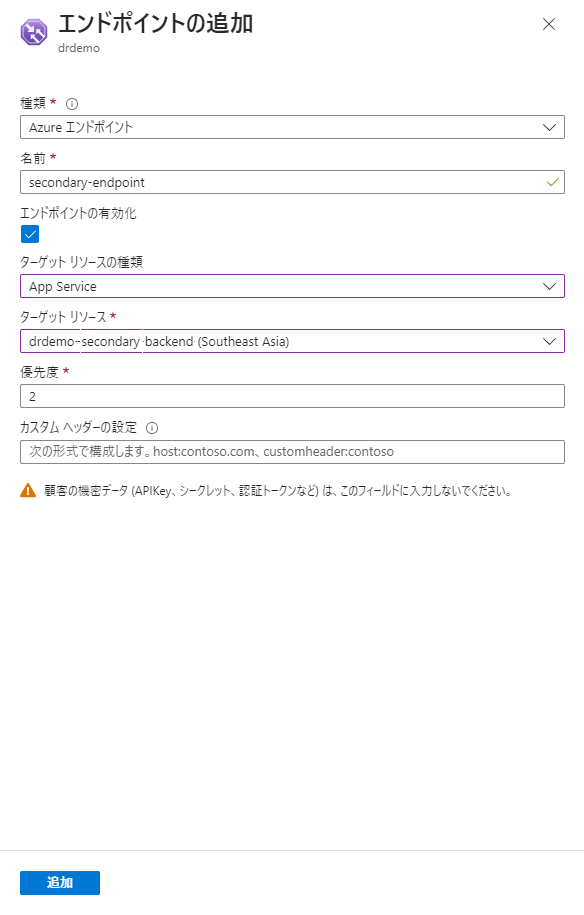
プライマリー、セカンダリーともにエンドポイント追加ができました。ただ、モニターの状態が両リージョンとも「低下」になっています。これはすべてのバックエンドAzure Functionsの正常性が確認できないためトラフィックマネージャーは機能していない状態です。これを解決していきます。
Traffic ManagerはデフォルトでHTTPで正常性チェックを行います。ですのでその構成を変更してあげて、HTTPSでトラフィックマネージャーがAzure Functionsと疎通できるようにします。
トラフィックマネージャーの構成設定に移動し、エンドポイントモニターの設定でプロトコルを「HTTP」から「HTTPS」に、ポートを「80」から「443」に変更しましょう。変更したら「保存」をクリックします。正常性チェックのカスタムコードなどがある場合はパスに記述します。Azure Functionsとかでしたら、healthcheckという関数を追加したとしたらapi/healthcheckと入れる感じですかね。200を正常として扱い、それ以外のステータスコードを使うようなら「状態コードの範囲が必要です」に定義してあげます。今回は特に行いません。ルートへのGETリクエストで200が返ってくれば正常と扱います。
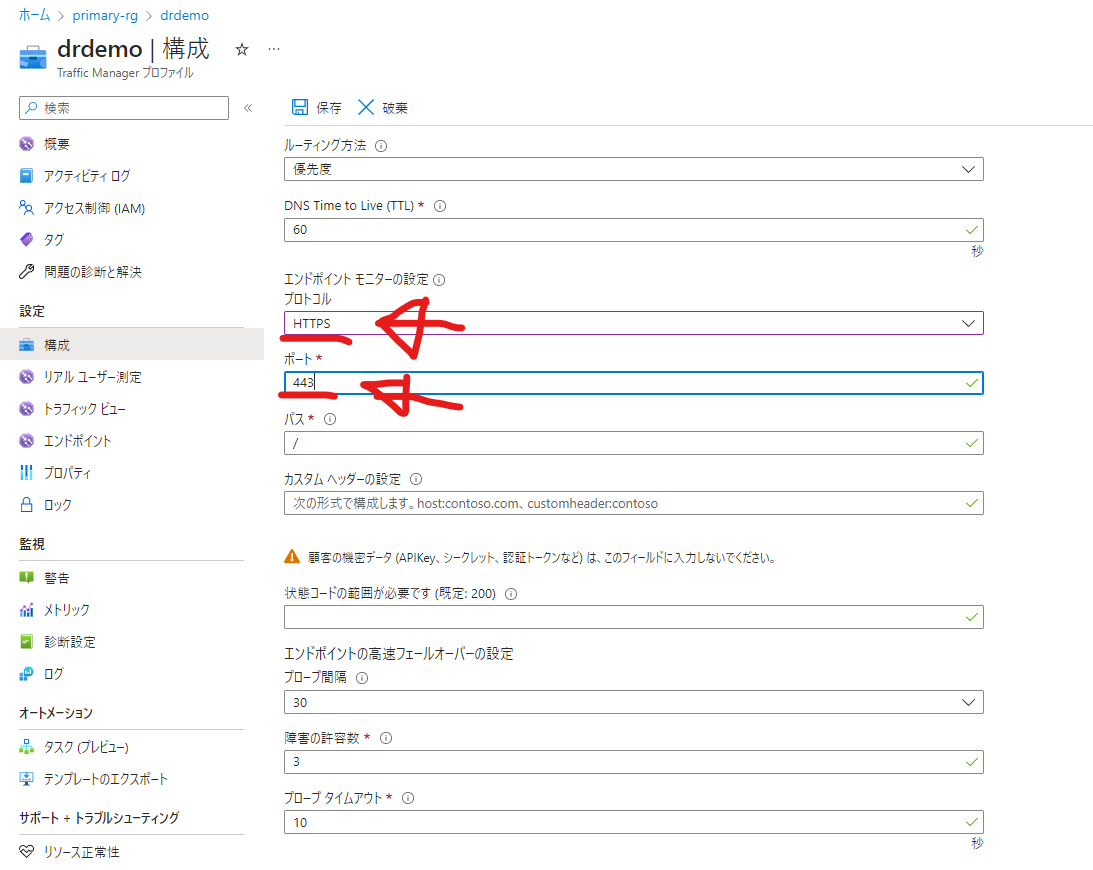
この状態でモニターの状態を確認すると、ばっちりオンラインになってました。OKです。
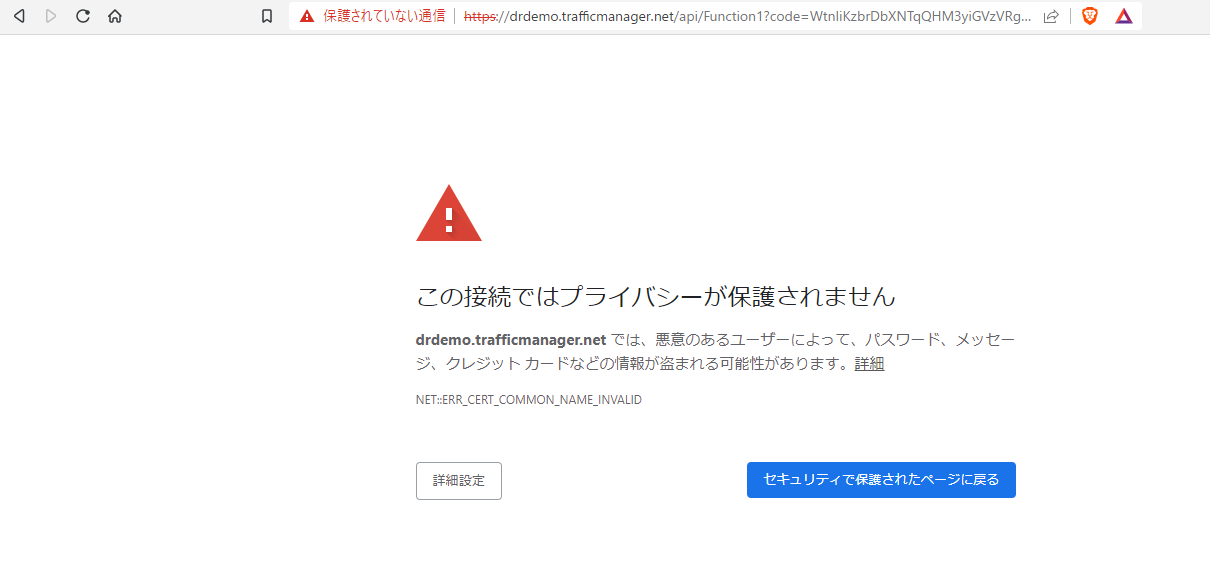
一度、これでアクセスしてみます。トラフィックマネージャー経由のアクセスはAzure Functionsのエンドポイントのホスト名をトラフィックマネージャープロファイル作成時に指定した「名前.trafficmanager.net」にするだけです。が、「この接続ではプライバシーが保護されません」が出てSSLでAzure Fucntionsと疎通できません。さすがにAzure Functions側で「HTTPSのみ」をオフにするっていうのも気が引ける・・・。
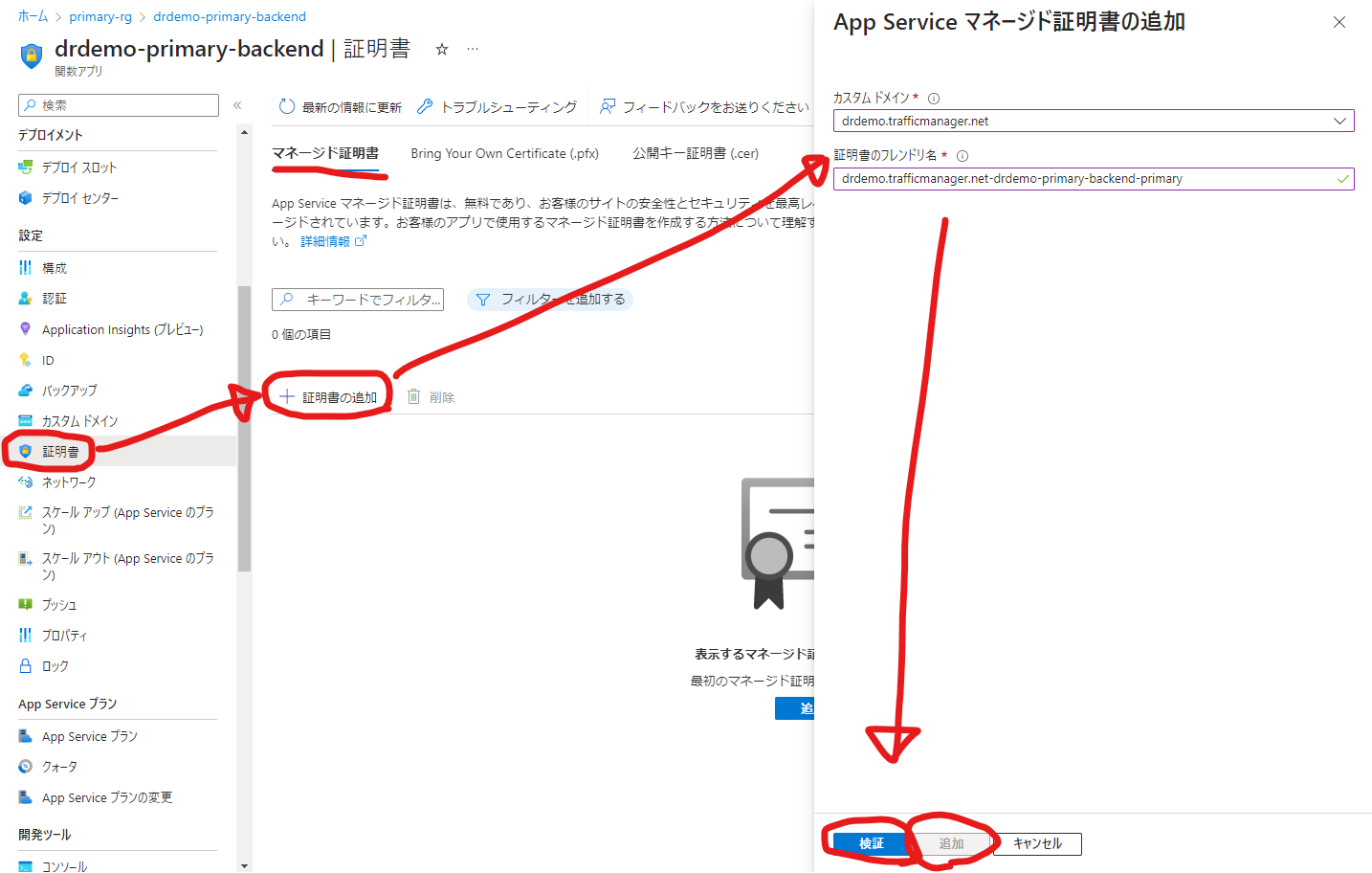
これに対処するためには、無料のAppServiceマネージド証明書を利用していきます。いいですよね「無料」っていう響き。とっても助かります。ありがとうAzure。ありがとうMSさん。
まずはAppServiceマネージド証明書を追加していきます。Azure Functionsの証明書に移動し、「証明書の追加」をクリックします。カスタムドメインにはTrafficManagerのホスト名、証明書のフレンドリ名を入力し検証、追加を行いましょう。
※ちなみにカスタムドメインからAppServiceマネージド証明書の新規作成もできるのでそちらで行えば一手少なくできますね。
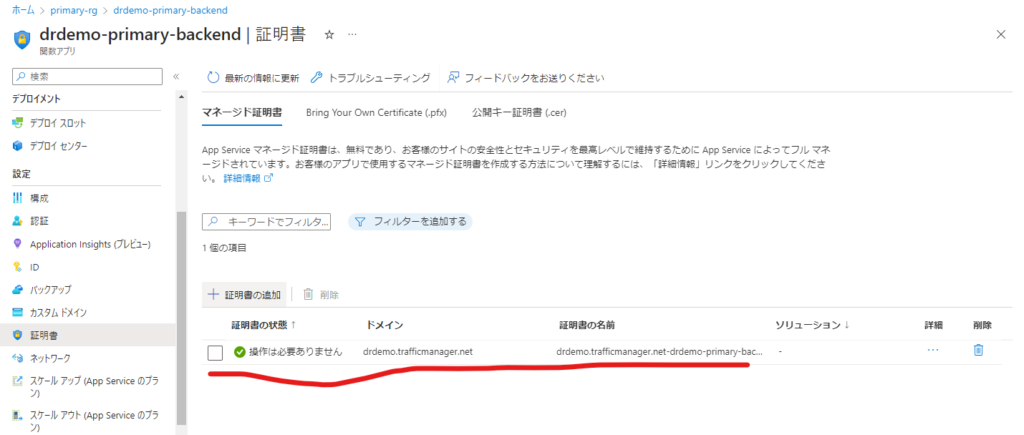
簡単にマネージド証明書が追加できました。
次にAzure Functionsにカスタムドメインを設定していきます。設定のカスタムドメインを選択すると以下のような画面になります。「バインディングの追加」を選択します。
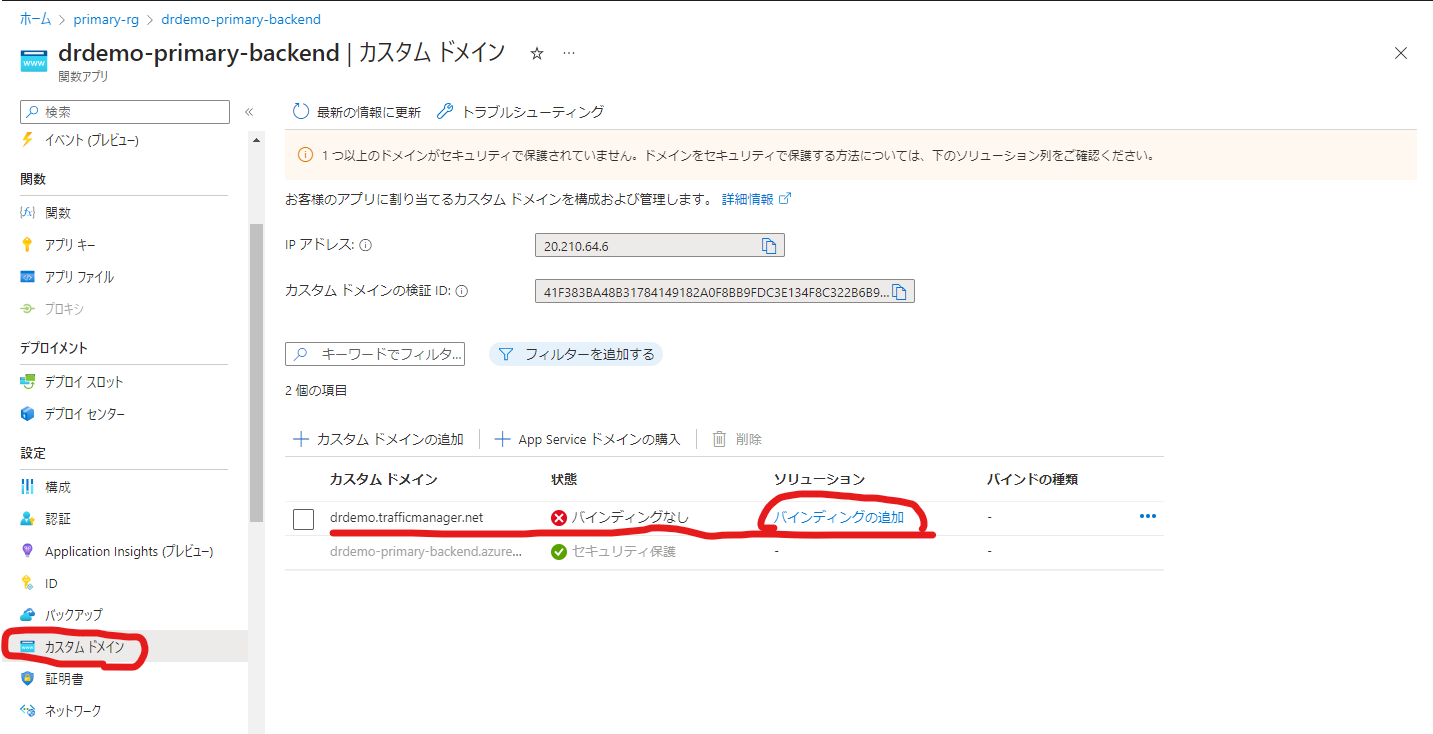
TLS/SSLバインドの追加で証明書として先ほど作成したAppServiceマネージド証明書を選択し、追加を行いましょう。
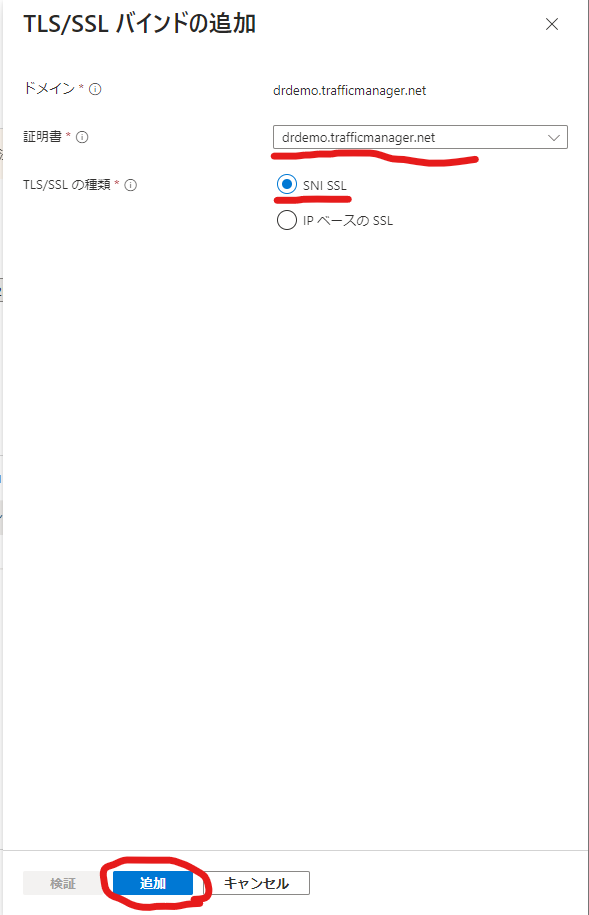
無事トラフィックマネージャーのドメインがカスタムドメインとして追加され、セキュリティ保護されました。忘れずにセカンダリーの証明書、カスタムドメインの設定もお願いしますね。
で、セカンダリーの証明書作成時に以下のエラーが出ました。
TrafficManager上からプライマリーエンドポイントの優先順位を一時的にセカンダリーより落としてあげてから、セカンダリーAzure Functionsのカスタムドメイン&証明書の追加を行ったらうまくいきます。
もう一度、トラフィックマネージャー経由のエンドポイントでAzure Functionsを呼び出してみます。無事プライバシーエラーで怒られることもなくトラフィックマネージャー→Azure Functions→VNET→プライベートエンドポイント→Azure SQL Databaseの呼び出しまで完了したことが確認できました。うぇ~~~~いwww

稼働確認
最後にDR構成がうまくいっているか稼働確認していきましょう。
※レスポンスが正しく返ってくるかのみを検証します。
シチュエーションは以下の4パターンかなと。
| パターン | Azure Functions | Azure SQL Database |
|---|---|---|
| パターン1:通常運用 | プライマリー | プライマリー |
| パターン2:SQL障害 | プライマリー | セカンダリー |
| パターン3:バックエンド障害 | セカンダリー | プライマリー |
| パターン4:プライマリーリージョン障害 | セカンダリー | セカンダリー |
パターン1:通常運用
バックエンドもデータベースもプライマリーリージョンの通常運用パターン。
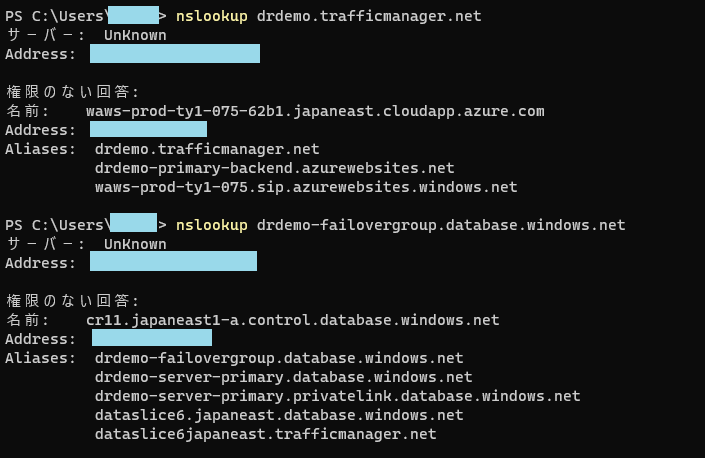
これはいいでしょ。

パターン2:SQL障害発生
バックエンドは問題ないが、プライマリーのAzure SQLに障害が発生してセカンダリーにフェールオーバーしたパターン。
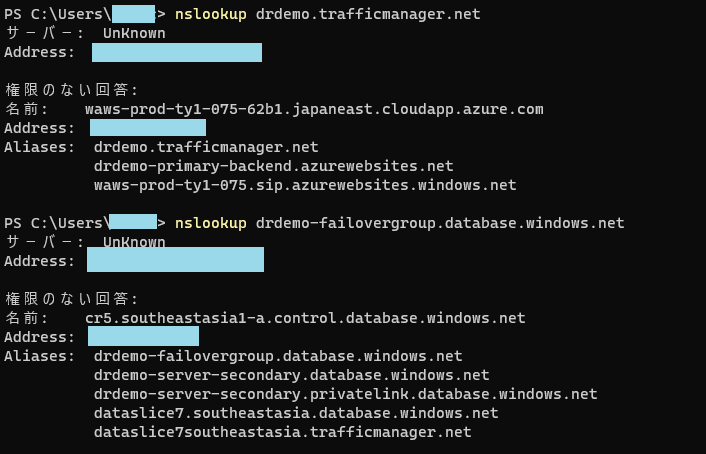
これもOK。問題なし。

パターン3:バックエンド障害
バックエンドに障害発生でセカンダリーのバックエンドにトラフィックが振り分けられ、データベースはプライマリーに書き込まれるパターン。
※Azure Functionsの認証対策してないので関数キーはセカンダリーのものを使用します・・・。
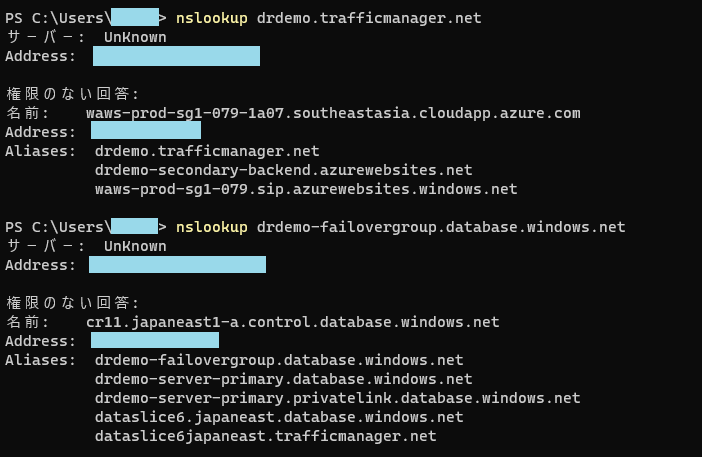
おぉ。バッチリ。TrafficManagerもちゃんと働いています。

パターン4:プライマリーリージョン障害
最後は東日本リージョンがごっそり災害等で使えなくなった場合。すべてセカンダリーで稼働を想定。
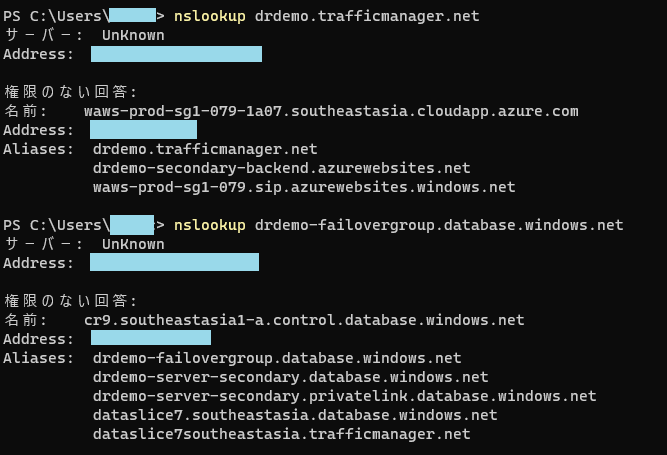
パーフェクト!!バッチリセカンダリーのリソースで稼働しました。

ひとまず、DR構成でのWEBアプリ出来上がりましたが、トークンの件とか関数キーの課題がありますのでその辺までフルスケールで行うにはAPIゲートウェイとかFront Doorやっぱ必要なんですかね。
追記:Azure Front Doorを利用したDR構成例も投稿してみましたのでご参照ください。
まぁ再認証かませればこの構成でもなんとか行けなくはないのかなぁと。
2024/08/17追記
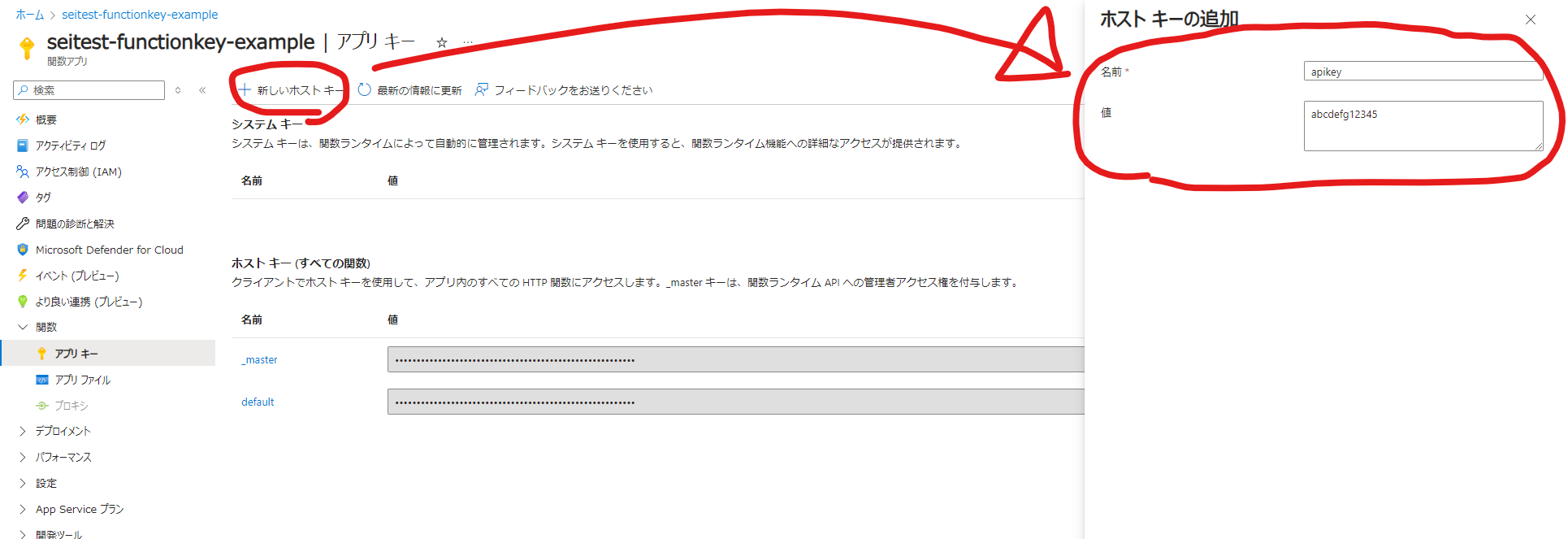
Azure Functionsのアプリキーって自動生成されるものしか利用できないと勘違いしてましたが、新規で追加することできましたね。なので、「新しいホストキー」でプライマリー、セカンダリー共通のホストキーを用意しておいてあげればフェールオーバーしても共通のアプリキーを利用してシームレスにAzure Functionsを利用できそうな気がしますね。まぁ設計によるとおもいますが。にしても、以前からホストキーの追加ってできましたっけ・・・?
→さらに追記。アプリキーを新規で作成するまでもなく、既存のアプリキーを編集することができるので、プライマリーとセカンダリーで同一のアプリキーに統一することは簡単にできますので、お試しください。
プライベートエンドポイントかませてストレージなんかも入れてあとはよしなに。
東日本がいっちゃったときに本当にオレら平気なの?っていうのはあるんですがね。。。対策してるのとしてないのでは気持ちのあり方が全然違いますよねぇ。
ってことで大分長丁場になってしまいましたが、無事DR構成を構築することができました。めでたしめでたしw



コメント